eBPF: From BPF to BPF Calls to Tail Calls
Site link: https://www.ebpf.top/post/bpf2pbpf_tail_call
Author: Richard Li (Original author’s permission obtained)
Original article link: https://blog.csdn.net/weixin_43705457/article/details/123474244
1. Introduction
This article first introduces the general restrictions and usage of tail calls, compares them with BPF to BPF calls, and finally provides a modified version I made of the tail call sample in the kernel source code (using CO-RE). (When learning about tail calls, I struggled with not having a simple and understandable example that could run, so I ended up creating one myself. I believe this version is the most beginner-friendly and logically clear among all examples currently available).
2. Tail Call
BPF provides a capability to safely inject code when kernel events and user program events occur, allowing non-kernel developers to control the kernel. However, due to inherent limitations such as 11 64-bit registers and 32-bit subregisters, a program counter, a 512-byte BPF stack space, and 1 million instructions (5.1+), and a maximum recursion depth of 33, the achievable logic is limited (not Turing complete).
The kernel stack is valuable, and in general, BPF to BPF calls will use additional stack frames. The biggest advantage of tail calls is the reuse of the current stack frame and a jump to another eBPF program, as described in [5]:
The important detail that it’s not a normal call, but a tail call. The kernel stack is precious, so this helper reuses the current stack frame and jumps into another BPF program without adding extra call frame.
eBPF programs are independently verified (values in the caller’s stack and registers are inaccessible to the callees), so state transfer is typically done using per-CPU maps. Tail call can also use special data items like skb_buff->cb for data transfer [8]. Furthermore, only BPF programs of the same type can be tail-called, and they must match with the JIT compiler. Therefore, a given BPF program is either JIT-compiled or interpreted (invoke interpreted programs).
The steps for tail calls require coordination between user space and kernel space and primarily consist of two parts:
-
User space: A special map of type
BPF_MAP_TYPE_PROG_ARRAY, storing a mapping of custom indexes tobpf_program_fd. -
Kernel space: The
bpf_tail_callhelper function, responsible for jumping to another eBPF program. Its function definition is as follows:static long (*bpf_tail_call)(void *ctx, void *prog_array_map, __u32 index). Here, ctx represents the context, prog_array_map is the aforementioned map of typeBPF_MAP_TYPE_PROG_ARRAY, used for user space to set up the mapping of the jump program and user-customized index. Index is the user-defined index.
If bpf_tail_call runs successfully, the kernel immediately runs the first instruction of the new eBPF program (never returns to the previous program). If the target program to jump to does not exist (i.e., the index does not exist in the prog_array_map), or the program chain has reached the maximum tail call limit, the call may fail. If the call fails, the caller continues executing subsequent instructions.
In [5], we can see the following text:
The chain of tail calls can form unpredictable dynamic loops, therefore, tail_call_cnt is used to limit the number of calls and currently is set to 32.
This limit in the kernel is defined by the macro MAX_TAIL_CALL_CNT (inaccessible from user space), currently set to 32 (I do not know what this so-called unpredictable dynamic loops refers to).
In addition to saving kernel stack space, I believe the biggest advantages of tail calls are:
- Increasing the maximum number of executable eBPF program instructions
- eBPF program orchestration
The above two advantages are not baseless. Let me explain with two examples for each point:
-
In [10], there is an eBPF program in BMC with a large loop. Although the eBPF program is only 142 lines long, the bytecode has already reached over 700 thousand lines. Without logical splitting, it would be rejected in the verification phase.
-
[9] proposes an eBPF orchestration strategy that allows arbitrary combinations of eBPF programs through a configuration file. It gives me the impression of creating a third-party storage, automatically fetching the required eBPF programs through configuration, and then automatically orchestrating, loading, and executing them. The orchestration process here is implemented using tail calls. The basic process is as follows:
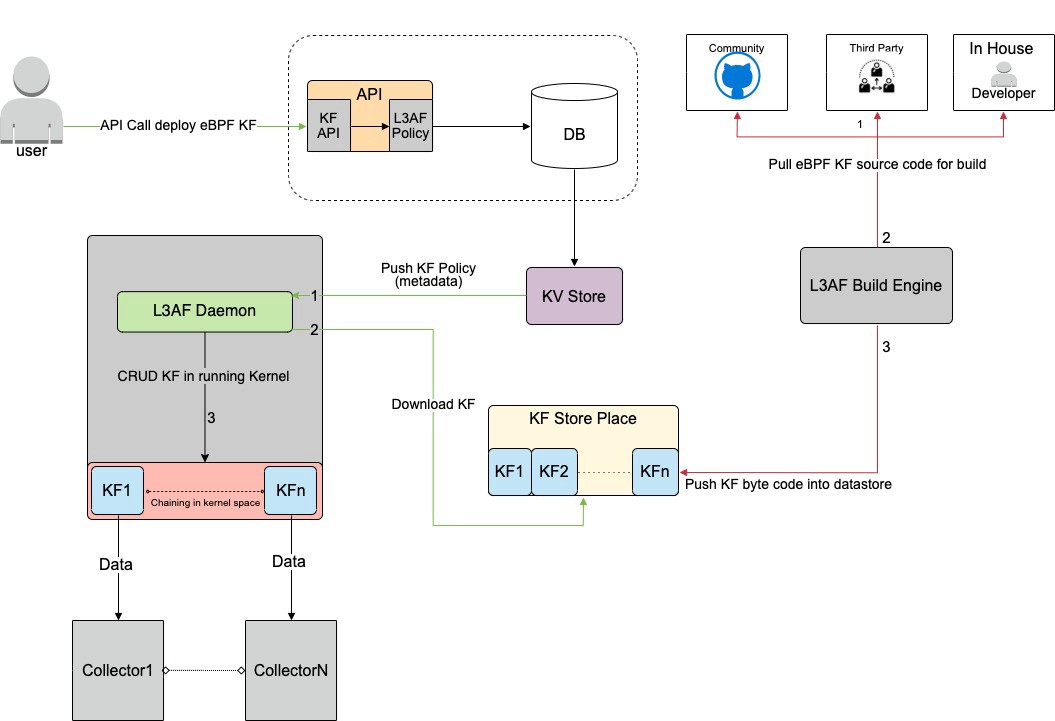
3. BPF to BPF Calls
Starting from Linux 4.16 and LLVM 6.0, this restriction has been resolved, and support for function calls has been added in loaders, verifiers, interpreters, and JITs.
The significant advantage is reducing the size of generated BPF code, hence being more friendly to the CPU instruction cache. The BPF helper function calling convention also applies to calls between BPF functions, with r1 - r5 used to pass parameters and the return result stored in r0. r1 - r5 are scratch registers, and r6 - r9 are reserved registers as usual. The maximum nested call depth is 8. The caller can pass pointers (e.g., pointing to the caller’s stack frame) to the callee.The disadvantage of tail calls is that the generated program image is large but saves memory; while the advantage of BPF to BPF Calls is a smaller image size but greater memory consumption. Before kernel 5.9, tail call and BPF to BPF Call cooperation was not allowed. However, on the X86 architecture after 5.10, both types of calls can be used simultaneously.
It is mentioned in [7] that there are certain limitations when using both types simultaneously, otherwise it may lead to kernel stack overflow:
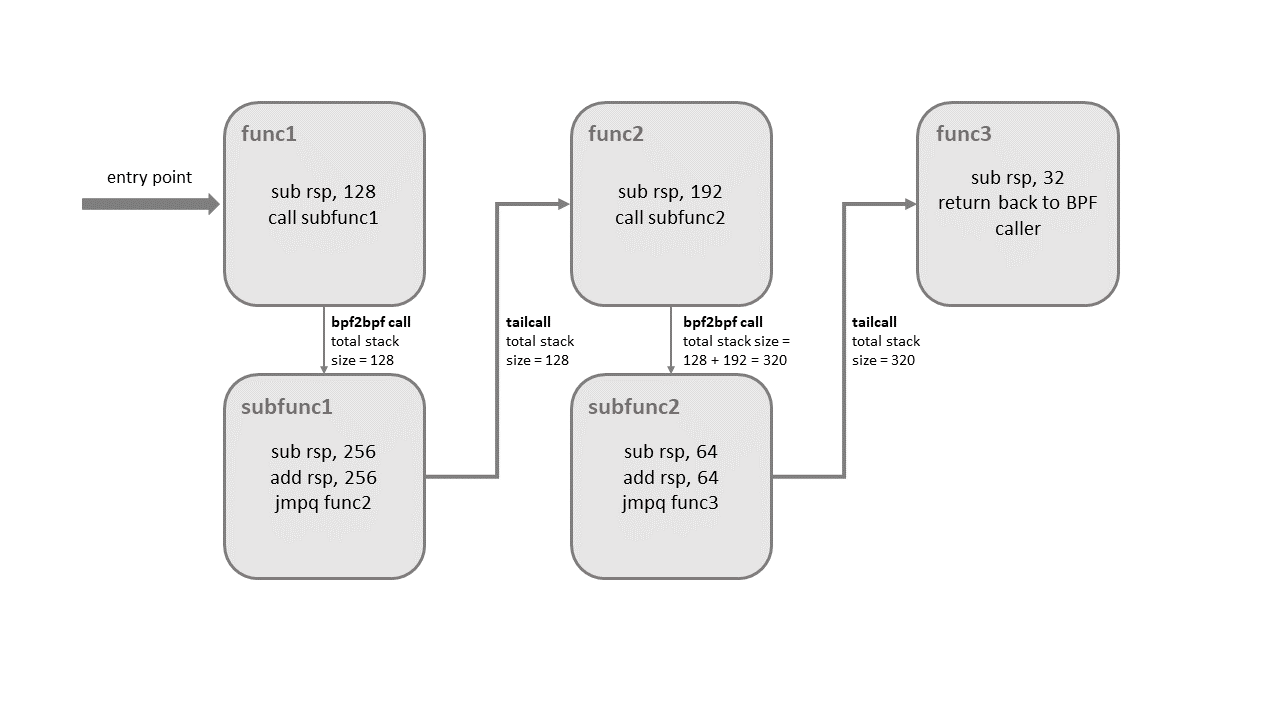 Taking the example of the call chain in the above figure, the limitation mentioned is that the stack space for each subprogram cannot exceed 256 bytes (if the verifier detects a bpf to bpf call, the main program will also be treated as a subprogram). This constraint allows BPF program call chains to use a maximum of 8KB of stack space, calculated as 256 bytes/stack multiplied by the maximum limit of 33 tail calls. Without this limitation, BPF programs would use 512 bytes of stack space, resulting in consuming up to 16KB of total stack space, potentially leading to a stack overflow on certain architectures.
Taking the example of the call chain in the above figure, the limitation mentioned is that the stack space for each subprogram cannot exceed 256 bytes (if the verifier detects a bpf to bpf call, the main program will also be treated as a subprogram). This constraint allows BPF program call chains to use a maximum of 8KB of stack space, calculated as 256 bytes/stack multiplied by the maximum limit of 33 tail calls. Without this limitation, BPF programs would use 512 bytes of stack space, resulting in consuming up to 16KB of total stack space, potentially leading to a stack overflow on certain architectures.
One thing to note here is how memory is saved when both types are used simultaneously. For example, when subfunc1 makes a Tail Call to func2, the stack frame of subfunc is already reused by func2. Then, when func2 makes a BPF to BPF Call to subfunc2, a third stack frame is created. Subsequently, when a Tail Call is made to func3, five logical processes utilize three stacks, saving memory.
Since subfunc1 was called initially, the program execution will eventually return to func1.
4. CO-RE Sample
We can see the official example of Tail Call in the kernel in [11][12]. I modified [11] using the libbpf CO-RE feature to make it easier for user programs to understand libbpf using Tail Call. Although mounting eBPF programs can be assisted using other commands like tc, prctl, I believe using the interface directly in the example program might be easier to understand. We use [11] as an example.
The example uses the seccomp filter, which is used to reduce the exposure of system calls in the kernel to applications, limiting the system calls each process can use (parameter modifications at the task_struct level). It supports two filtering modes, SECCOMP_SET_MODE_STRICT and SECCOMP_SET_MODE_FILTER, for restricting a subset (read, write, _exit, sigreturn) of filters and eBPF-style filters. [3] mentions that it can prevent TOCTTOU since open is restricted, naturally eliminating the risk of TOCTTOU errors [6].
Regarding the seccomp filter, [3] explains it as follows:
System call filtering isn’t a sandbox. It provides a clearly defined mechanism for minimizing the exposed kernel surface. It is meant to be a tool for sandbox developers to use.
[2] states:
Designed to sandbox compute-bound programs that deal with untrusted byte code.
tracex5_kern.bpf.c
|
|
tracex5_user.c
|
|
Run the following commands:
-
clang -g -O2 -target bpf -D__TARGET_ARCH_x86 -I/usr/src/kernels/5.4.119-19-0009.1(you should change it to your own)/include/ -idirafter /usr/local/include -idirafter /usr/include -c trace.bpf.c -o trace.bpf.o
-
gen skeleton trace.bpf.o > trace.skel.h
-
clang -g -O2 -Wall -I . -c trace.c -o trace.o
-
clang -Wall -O2 -g trace.o -lelf -lz -o trace
-
cat /sys/kernel/debug/tracing/trace_pipe
You can see the expected output.
5. Tail Call Costs in eBPF
[13] evaluates how much performance overhead some of the optimizations introduced to mitigate the Spectre vulnerability have on the tail call performance of eBPF (Spectre refers to a series of vulnerabilities exploiting hardware flaws present on most CPUs (Intel, AMD, ARM)).
I haven’t read this article yet. When I have the energy, I’ll take a close look at it, but for now, I’ll just glance at it.
6. Summary
I’m still struggling with the eBPF environment. I started running virtual machines on VMware Fusion, but M1 doesn’t support VMware Tools, making it extremely inconvenient to use, and the image also needs special modifications to run on M1 with a higher kernel version. Moreover, the cloud server version I purchased only goes up to 5.4.119, so some eBPF features cannot be used. As for running a dual system on a MAC M1, I don’t have the energy to tackle this crab. Firstly, there is little information available, and secondly, tail calls and BPF to BPF Calls simultaneous invocation is currently only supported on X86, with not much benefit.
Well, I admit, ultimately, I just don’t want to spend money on buying Parallels Desktop.
7. References
- Linux Security: Seccomp
- Using Seccomp to Restrict Kernel Attack Surface
- SECure COMPuting with Filters
- Seccomp(2) — Linux Manual Page
- BPF: Introducing bpf_tail_call() Helper
- Time-of-Check to Time-of-Use Wiki
- Cilium Document
- eBPF: Traffic Control Subsystem
- Introducing Walmart’s L3AF Project: Control Plane, Chaining eBPF Programs, and Open-Source Plans
- BMC: Accelerating Memcached using Safe In-kernel Caching and Pre-stack Processing
- Kernel: tracex5_kern.c
- Kernel: sockex3_kern.c
- Evaluation of Tail Call Costs in eBPF
- Author: Richard Li
- Link: https://www.ebpf.top/en/post/bpf2pbpf_tail_call/
- License: This work is under a Attribution-NonCommercial-NoDerivs 4.0 International. Kindly fulfill the requirements of the aforementioned License when adapting or creating a derivative of this work.
- Last Modified Time: 2024-02-07 00:28:29.526834788 +0800 CST

