Practical Guide to LSM BPF
This article is available at: https://www.ebpf.top/post/lsm_bpf_intro
1. Background on Security
Internationally, computer security is summarized by three main characteristics: Confidentiality, Integrity, and Availability (CIA).
- Confidentiality means that data is not visible to unauthorized individuals.
- Integrity refers to information not being altered during storage or transmission.
- Availability implies that one’s devices can be used when needed.
There are roughly four methods that computer systems employ to address security challenges: isolation, control, auditing, and obfuscation.
Access control involves controlling access, representing the subject’s actions on objects. Access control primarily involves defining subjects and objects, operations, and setting access policies. Generally, subjects are processes running in the system, while objects are kernel resource objects including files, directories, pipes, devices, sockets, shared memory, message queues, and other system resources.
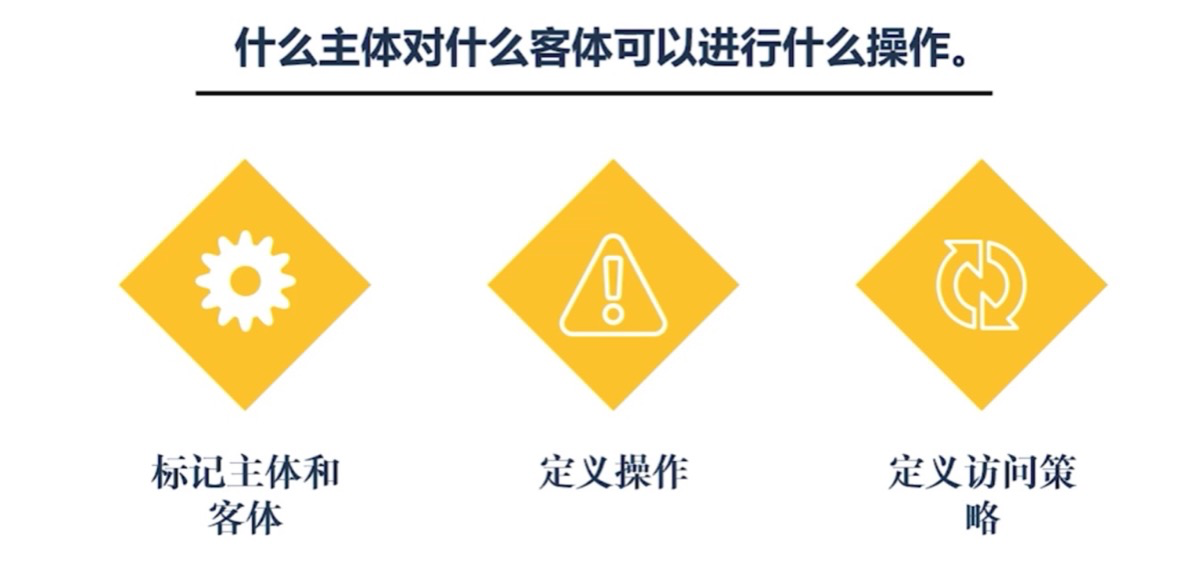
Regarding access control from a user control perspective, it can be divided into:
- Discretionary Access Control (DAC): where resource owners determine who can access and what actions they can perform.
- Mandatory Access Control (MAC): a stricter access control method where access permissions are managed and controlled by policies predefined by administrators or experts, which regular users in the system cannot alter.
For insights into kernel security, you can watch the video Introduction to Kernel Security, created by Li Zhi, the author of the book “In-depth Analysis of Linux Kernel Security Modules.”
The development of Linux kernel security began in the mid to late 1990s. After more than 20 years of development, the Linux kernel now has a fairly comprehensive range of security-related modules, including LSM for mandatory access control, IMA and EVM for integrity protection, key management modules and encryption algorithm libraries for encryption, as well as logging and auditing modules, in addition to various other security enhancement features. The focus of this article, LSM (Linux Security Module), is a general kernel security framework related to mandatory access control (MAC).
2. General Framework of Kernel Security Policy Module LSM
2.1 Introduction to LSM Framework
LSM (Linux Security Module), while translated as kernel security module in Chinese, is actually a lightweight security access control framework built on various security modules within the kernel. The framework simply provides an interface that supports security modules, without enhancing system security itself. The specific work is done by the individual security modules. In simpler terms, LSM sets the stage, and concrete modules are needed to play the role.
LSM in the kernel consists of a set of security-related functions that are essential components for implementing mandatory access control (MAC) modules, enabling policies to be decoupled from kernel source code. These security functions are called in the execution path of system calls, implementing mandatory access control for user-space processes accessing kernel resource objects, including files, directories, task objects, credentials, etc. Starting from version 5.4, this framework currently includes 224 hooks across the entire kernel, an API for registering functions to be called on these hooks, and an API for preserving memory associated with protected kernel objects for LSM use. For further details, refer to the Kernel Documentation LSM section.
As of kernel version 5.7, there are a total of 9 LSM security module implementations: SELinux, SMACK, AppArmor, TOMOYO, Yama, LoadPin, SafeSetID, Lockdown, and BPF (supported from version 5.7). The primary implementations of security modules are shown in the following diagram:
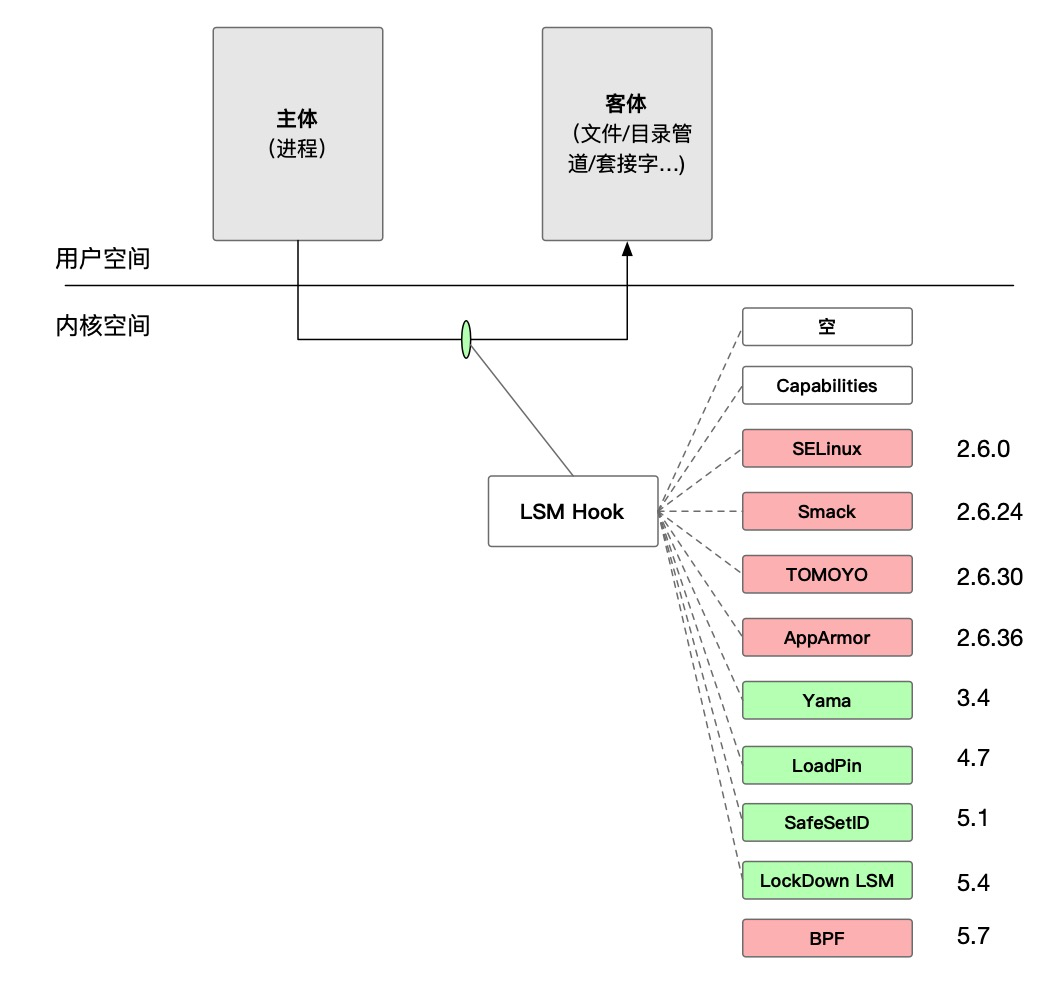
Seccomp and LSM both can restrict process and system interactions at the kernel level, where seccomp is about limiting the system calls processes can make, while LSM is about controlling access to objects within the kernel. To delve deeper into the differences and connections between LSM and the secure computing mode seccomp, you can read LSM vs seccomp.
Regarding Major and Minor LSMs:
-
Major LSMs: Implement MAC by loading configuration policies from user space, allowing only one LSM to be used at a time. They assume exclusive access to security context pointers and identifiers embedded in protected kernel objects, examples are SELinux, SMACK, AppArmor, and TOMOYO.
-
Minor LSMs: Implement specific security functionalities, stack atop major LSMs, and usually require less security and context. Minor LSMs typically only contain flags for enabling/disabling options, instead of loading policy files from user space as part of the system. Examples include Yama, LoadPin, SetSafeID, and Lockdown.

For a comprehensive introduction to LSM, further references can be found in An Overview of Linux Security Modules and LSM, the Security Shield of Linux Kernel.
2.2 Architecture of LSM
The LSM framework offers a modular architecture with built-in “hooks” in the kernel, allowing the installation of security modules to strengthen access control.
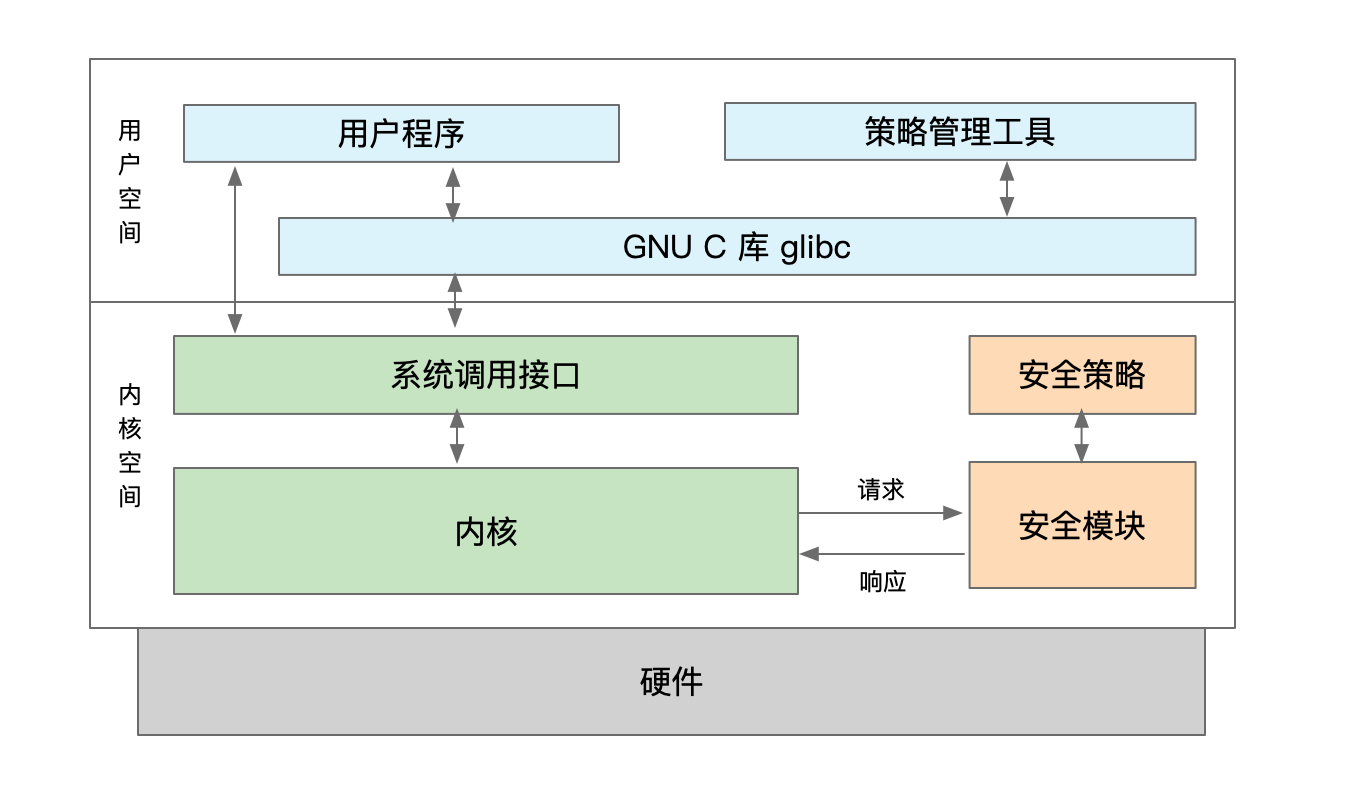
The LSM framework mainly consists of five major components:- **Added a security domain to key specific kernel data structures, such as struct file structure with void *f_security;.
- Inserted calls to security hook functions at different key points in the kernel source code.
- Provided a generic security system call that allows security modules to write new system calls for security-related applications, styled similarly to the original Linux system call
socketcall(), which is a multiplex system call. - Implemented registration and deregistration functions so that access control policies can be implemented as kernel modules, primarily through
security_add_hooksandsecurity_delete_hooks. - Transformed most of the capabilities logic into an optional security module.
In the specific implementation, the LSM framework controls operations on kernel objects by providing a series of hooks, essentially using the hook injection method. Taking the example of accessing the file open function process, the access diagram of hook functions is as follows:
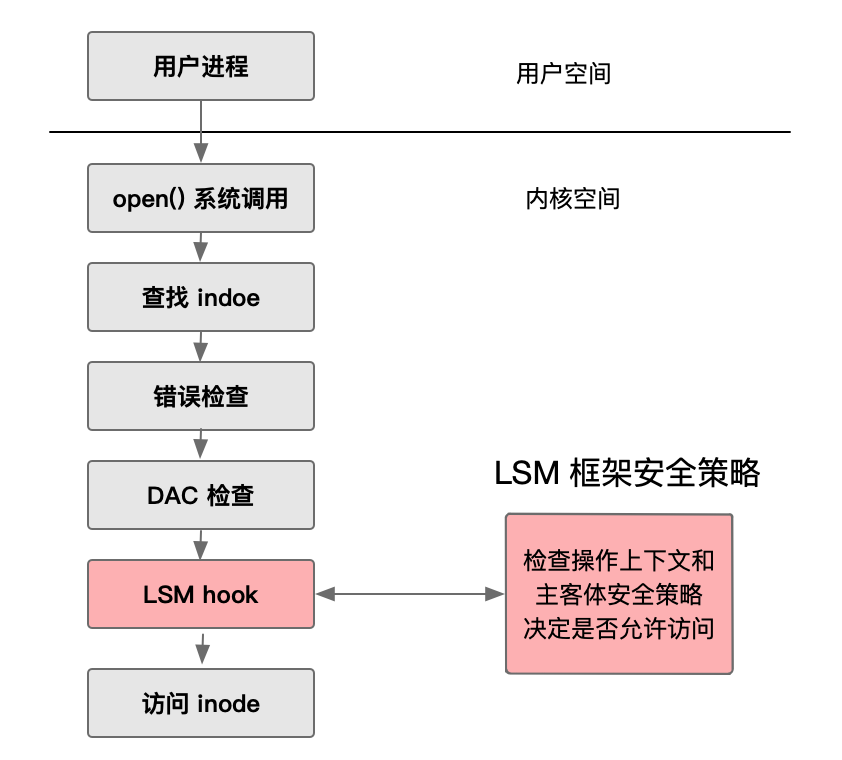
- After entering the kernel through a system call, the system performs an error check first.
- Once the error check passes, it proceeds with traditional permission checks, namely Discretionary Access Control (DAC) checks (traditional permission checks are primarily based on users, allowing resource access once the user is verified).
- Only after passing these checks, Mandatory Access Control (MAC) is enforced. MAC is a type of access control that prohibits subjects from interfering, utilizing security labels, information classification, and sensitivity to control access, determining access based on comparing the subject’s level and the sensitivity of the resource.
For further details on LSM implementation, it is recommended to read Deep Understanding LSM pdf.
2.3 Hook Functions in LSM
The core concept behind LSM is LSM hooks. LSM hooks are exposed at critical positions within the kernel and can control operations through hooks, such as:
- File system operations
- Opening, creating, moving, and deleting files
- Mounting and unmounting file systems
- Task/process operations
- Allocating and freeing tasks, changing task user and group identities
- Socket operations
- Creating and binding sockets
- Receiving and sending messages
All LSM hooks in the system can be viewed in the Linux kernel source code header file lsm_hooks.h [kernel 6.2.0]. Different operations and corresponding scenarios can be found in the header comments. In kernel 6.2.0, the categories include:
|
|
Each defined hook function includes corresponding arguments that provide context for which programs can enforce policy decisions and are listed in lsm_hook_defs.h. In kernel version 6.2.0, there are 247 defined functions. Here are some sample definitions:
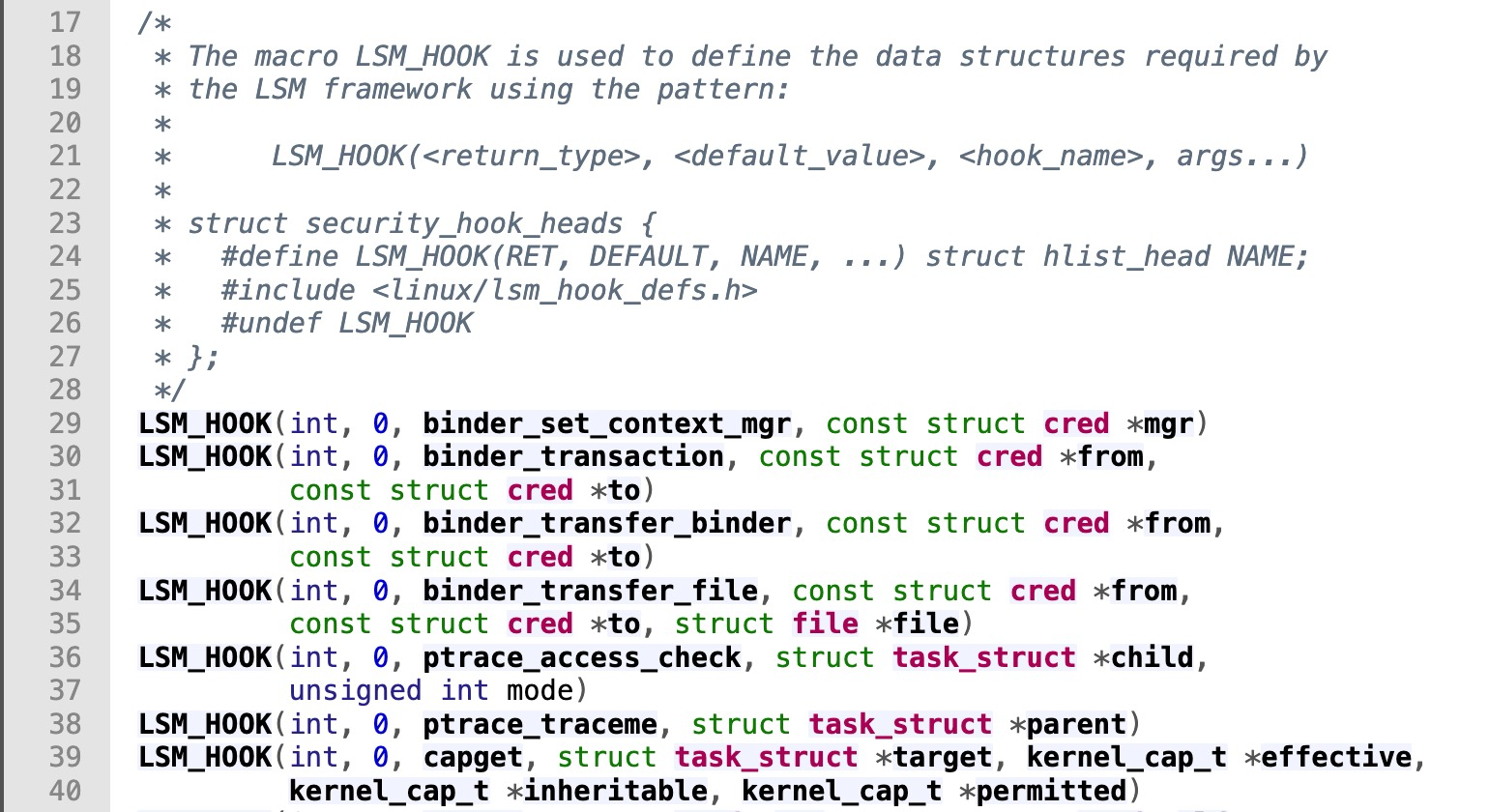
The LSM_HOOK definition format is as follows:
|
|
Most hooks provided by LSM return an integer value (some return void, indicating to ignore the execution result). The return values are generally defined as:
- 0: Equivalent to authorization.
- ENOMEM: Out of memory.
- EACCESS: Security policy denies access.
- EPERM: Requires permission to execute this operation.
3. LSM BPF
Before LSM BPF was introduced, there were two options to implement security policies: configuring existing LSM modules (such as AppArmor, SELinux), or writing custom kernel modules. LSM BPF brings a third implementation solution, offering flexibility, security, and programmability.The introduction of LSM BPF, abbreviation for LSM Berkeley Packet Filter, was included in Linux 5.7. With LSM BPF, developers are able to craft fine-grained policies without the need to configure or load kernel modules. LSM BPF programs are validated upon loading and executed when reaching the LSM hook in the call path. These BPF programs allow privileged users to perform runtime checks on LSM hooks, enabling the implementation of system-wide Mandatory Access Control (MAC) and auditing policies using eBPF.
As of kernel version 6.2.0, there are 7 LSM hook functions related to BPF security itself. These are controlled by the compilation conditional macro CONFIG_BPF_SYSCALL and mainly involve BPF system calls, BPF programs, and BPF map operations:
|
|
Before proceeding to write LSM BPF programs, ensure the following:
- The kernel version is at least 5.7.
- LSM BPF is enabled.
Verification of LSM BPF activation can be done as follows, and the correct output should include bpf:
|
|
If not so, LSM BPF must be manually enabled by adding it to the kernel configuration parameters. In my local Ubuntu 22.04 system, ‘bpf’ was not included in the output, requiring manual activation.
Modify the GRUB configuration /etc/default/grub and add the following content to the kernel parameters:
|
|
Then, rebuild the GRUB configuration by running the update-grub command to take effect:
|
|
Upon confirming the addition to the boot parameters, restart the system for it to take effect.
3.1 BCC Practice
The BCC project has already provided LSM function support, and we can define functions using the LSM_PROBE macro. Here, we implement a feature to prohibit calling the bpf() system call. After this program runs normally, any invocation related to the bpf() system call will result in a permission denied message, using magic to defeat magic:
|
|
The normal execution result is as shown below:
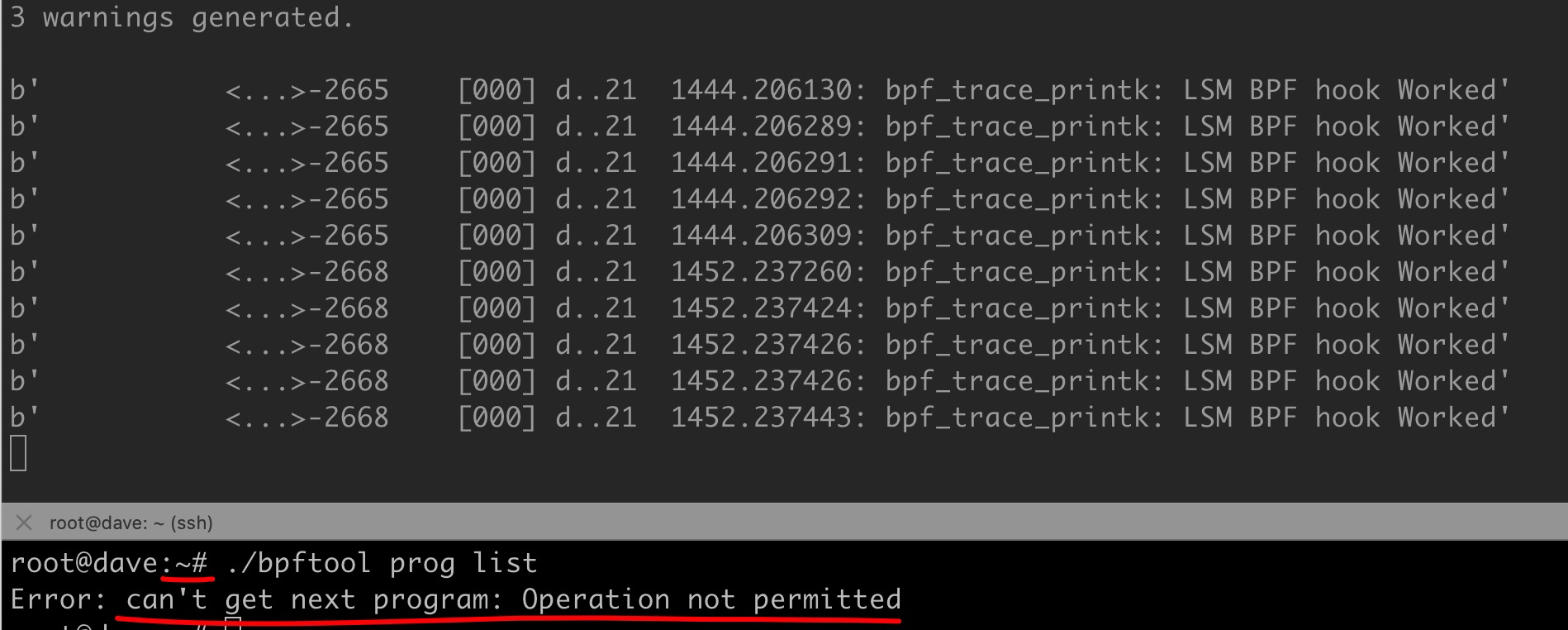
It is important to note that if the GRUB parameters are modified to include bpf but the system is not restarted, running the above program will produce errors, without achieving the desired effect. Even after running the program, commands can still be executed using the bpftool parameter:
|
|
This discrepancy occurs because BPF.support_lsm() in the code only statically checks if the system has enabled BTF and declared the bpf_lsm_bpf function symbol, without accurately reflecting whether BPF support in LSM is enabled.
|
|
bpftrace currently does not support LSM BPF. Related work is under discussion and development. For more information, refer to Support attaching to bpf LSM hooks.
3.2 libbpf-bootstrap Framework Practice
For environment setup, refer to the official repository’s building section. Introductions to libbpf-bootstrap documentation can be found at Building BPF applications with libbpf-bootstrap.
Add lsm.bpf.c in the /examples/c directory:
|
|
One thing to note here is the additional int ret at the end of the function. This is because LSM hooks are managed in a linked list manner. ret is used to provide feedback on the result of the previous BPF program’s execution. If the current running BPF is the first one, the value of ret is 0.
Modify the Makefile:
|
|
Run the compilation command, which will automatically generate the lsm.skel.h file. Upon successful compilation, the binary file lsm will be generated:
|
|
The runtime effect is similar to what is written with BCC:
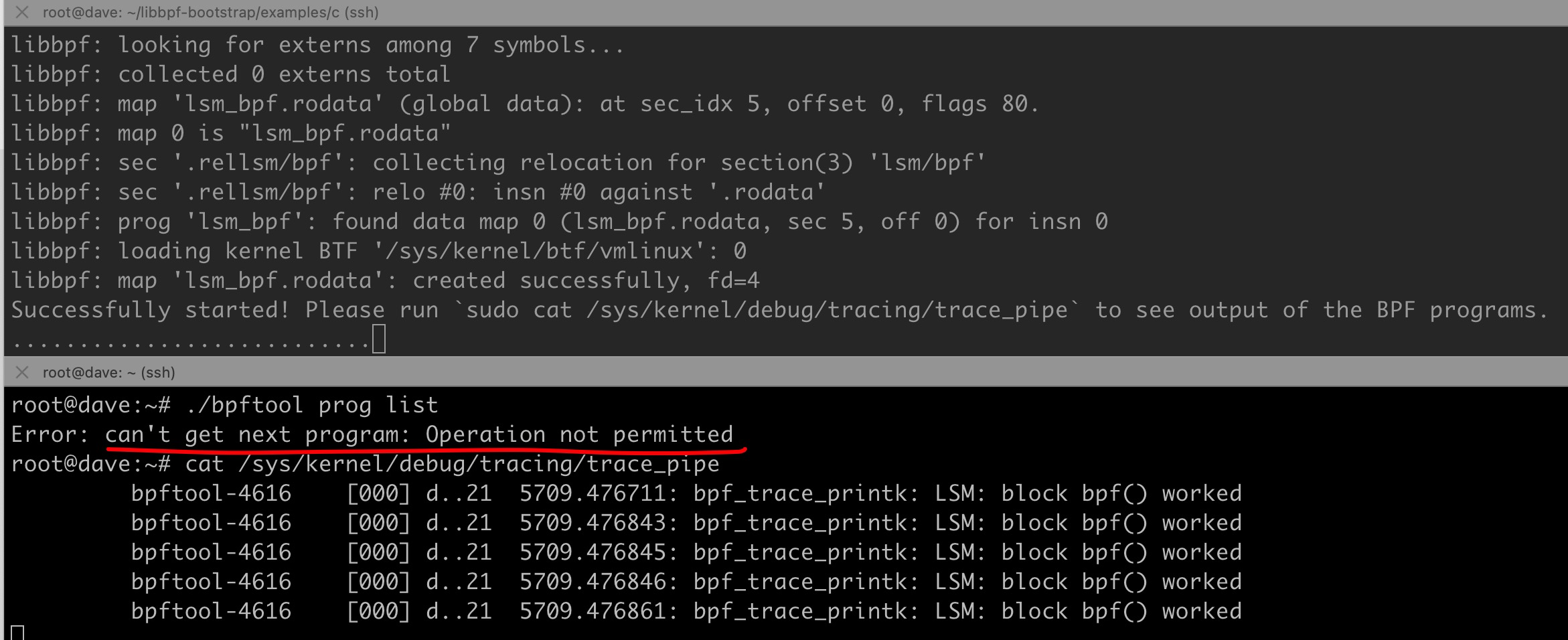
Additionally, code based on the cilium/ebpf Go library can be found in the lsm-ebpf-experimenting repository, but it’s not shown here.
4. Summary
This article briefly introduced the fundamental knowledge of LSM framework and provided examples of BCC and libbpf library implementations based on LSM BPF. Hopefully, it will help you quickly get started with LSM BPF programming. For further understanding of the application scenarios of LSM BPF, it is recommended to read Live Patch Security Vulnerabilities with eBPF LSM. In this article, the author presented a complete practice of risk mitigation based on LSM BPF in the context of elevating privileges through the USER namespace within a container environment, including principles, selecting hook functions, and implementing BPF code.
5. Appendix: Process of Finding LSM Hot Patch Kernel Vulnerabilities Monitoring Hook Points
The most challenging part of solving a problem is finding the key points that block the issue. In order to facilitate understanding, the process of determining the LSM hook points used in the eBPF LSM article for hot patching Linux kernel vulnerabilities is provided for reference. The complete BPF code can be found in lsm_bpf_monitoring.
Allowing non-privileged users to access the USER namespace always poses significant security risks. One of the risks is privilege escalation, a common attack surface for operating systems. Privilege escalation can be achieved by using the unshare syscall to map its namespace to the root namespace, specifying the CLONE_NEWUSER flag. This directs unshare to create a new user namespace with full privileges and map new user and group IDs to the previous namespace. You can use the unshare(1) program to map the root to our original namespace:Through the manual page, we can learn that unshare is used to alter tasks. Let’s take a look at the task-based hooks in include/linux/lsm_hooks.h. As early as the function unshare_userns(), we see a call to prepare_creds(). This bears a striking resemblance to the cred_prepare hook. To verify if we obtained a match through prepare_creds(), we observe the invocation of the security hook security_prepare_creds(), which eventually calls this hook:
|
|
Definition of the unshare system call
|
|
Within ksys_unshare(), the function called related to user is unshare_userns()
|
|
The source code for unshare_userns() is as follows:
|
|
The function prepare_creds() involves a call to the LSM hook:
|
|
For information on BPF and security, please refer to: https://lwn.net/Kernel/Index/#BPF-Security
- Author: DavidDi
- Link: https://www.ebpf.top/en/post/lsm_bpf_intro/
- License: This work is under a Attribution-NonCommercial-NoDerivs 4.0 International. Kindly fulfill the requirements of the aforementioned License when adapting or creating a derivative of this work.
- Last Modified Time: 2024-02-06 15:49:27 +0800 CST

