【BPF 攻防系列-2】【译】恶意使用的 bpftrace 🤯
本文地址:https://www.ebpf.top/post/offensive-bpf-bpftrace
本篇文章是我正在进行的关于 BPF 攻防系列 的一部分,用于学习 BPF 以了解相关的攻击和防御,请点击 “ebpf” 标签查看所有相关帖子。
我正在学习 BPF,以了解其使用将如何影响安全攻击、恶意软件和检测工程。

在 BPF 中最容易想到的想法是分析网络流量并基于特定事件采取行动。因此,我想看看流行的 BPF 工具 bpftrace,是否 / 如何被用来创建潜在的后门,以及作为防御者可以从哪里寻找到相关证据。
让我们开始吧。
1. 什么是 bpftrace
bpftrace 是一个多功能的工具,可用来创建自定义的 BPF 程序,而不需要处理太多底层技术细节。在 bpftrace 主页 中,将之称为 “Linux 系统中的高级跟踪语言 “,其对应的 logo 非常可爱。
bpftrace 有点像 BPF 技术中的瑞士军刀。
我的目标是从更高的层次学习 BPF 的基础知识,以熟悉其用途和限制。bpftrace 工具非常符合我的这种要求。

在使用 bpftrace 编写了几天程序后,我开始真正掌握了相关的窍门。
1.1 安装
性能和可观察性团队正在推动使用 bpftrace 工具编写相关的工具用于生产环境中,这应该会更多。
对于在你自己的 Linux 操作系统中实验 bpftrace,可参考 相关安装说明 。
注:我还将我的 Ubuntu 机器升级到了 21.04(内核 5.11),以方便使用最新的功能和调试能力,这这得我在学习 BPF 的过程中更加轻松。但样例应该也会在稍早期的版本上工作。
1.2 基本样例
这里的样例是学习 bpftrace 最基本的 “hello world”:
|
|
你能猜到其所实现的功能吗?
首先,让我们看看这些参数:
bpftrace需要以root的身份运行,或者具有CAP_BPF的能力(这里使用 `sudo’)。-e:定义bpftrace程序sys_enter_open跟踪点用于打印comm(进程名称)和args->filename。
这里有几个使用到的 神奇的变量,如 comm 和 args。
可以在 Brendan Gregg 的简易手册中进行学习,我经常用来查询变量名称和其他 bpftrace 功能。
该样例让我们了解到 BPF 程序有多强大。想象一下,hook 密码 API 调用或网络流量,就可以用于观察或获取相关数据。
1.3 使用 system() 的恶意行为
当然,我也在寻找一种能够在 BPF 程序中运行 shell 命令的方法,相对应的,bpftrace 有一个方便的 system() 命令可以实现该功能:
|
|
注意,这需要使用 --unsafe 选项。
检测提示 可以通过查找任何不安全的 bpftrace 用法。
2. 使用 bpftrace 建立后门
攻击者能做什么?让我们再深入了解一下:
- 假设一个攻击者获得了某台主机的特权访问。
- 攻击者安装了一个基于 “bpf” 的 TCP 后门。
- 现在,只要消息来自某个 IP(或源端口),恶意的程序就会运行。
- 客户 / 攻击者用于触发命令后门的 TCP 服务并不重要(HTTP、SSH、MySQL…) 🤯
这听起来很简单,但我花了很多时间(断断续续接近 3 天)才弄清楚最基本的东西,实现了这一目的。
这里,我将分享一下学习成果 – 这对任何想学习 BPF 的人来说也能提供帮助。
2.1 第一个方案:基于源端口触发
为了简单起见,也是因为最初的目的是学习 BPF 技术,我的第一次尝试是使用远程 IP 地址和 TCP 连接的神奇源端口号的组合来触发 BPF 程序。
假设一个数据包源端口为 6666,那么 BPF 程序就会被唤醒来执行恶意程序。
我使用 sudo bpftrace -l 'kprobe:*accept*' 来查找与 accept 相关可用的 kprobes 函数 …
再接再厉,我创建了 BPF 程序,将其 hook 在用于处理 TCP 请求连接的 kretprobe:inet_csk_accept 函数上。
事后想起来这相当简单,但我花了很多时间(几天)尝试各种 kprobes 和 traceppoint,经历了一系列的失败,才真正找到第一个可以解决问题的方案。
2.2 实现
当建立更复杂的程序时,将其保存在文件中更加方便。bpftrace 程序通常有 .bt 文件扩展名。
为保证 socket 数据结构是可用,在开始阶段我引入了 sock.h 头文件。
|
|
接着,我在命令行上为程序设置了有用的提示信息:
BEGIN
{
printf("Welcome to Offensive BPF... Use Ctrl-C to exit.\n");
printf("Allowed IP: %u (=> %s). Magic Port: %u\n", $1, ntop(AF_INET, $1), $2);
}
$1 和 $2 是传入的命令行参数(允许的 ip 和神奇的端口信息,都为整数类型)。
之后,探针的实现从监听的 kretprobe 开始。顺便说一下,总是有两个相应的探针 / 钩子,比如入口和返回(kret)探针。
|
|
接下来,我们将从 kretprobe 中获取套接字,并将其存储在 $sk 变量中,并同时打印出正在连接的远程 IP 信息。
|
|
接下来是该程序的核心逻辑。
首先,我们检查远程 IP 是否是被允许调用的命令。
|
|
为了解 struct sock * 和其他的布局,我特意查看了对应的 Linux 的头文件。
如果 IP 检查成功,那么我们检查连接的魔法端口是否也匹配:
|
|
- 这里有些处理稍微麻烦的事情,
skc_dport需要从 big endian 转换 - 这很合理。但由于某些原因,在进行转换之前,我们必须先读取本地端口(或访问 sk 结构)– 否则远程端口信息就会出错。目前这对我来说并不合理的,我还在努力了解下面发生了什么。我并不不确定这是否为 bpftrace 的问题 *。
总之,如果连接的远程端口与设定的端口一致(比如这里的 “6666”),那么我们就执行一个 system 命令。
|
|
注意 BPF 程序在这种情况下,可通过命名空间访问文件系统的方式。这又是一个花了我几个小时才弄明白的情况。
最后,bpftrace 程序也可以有一个 end 函数,在这里你可以清理分配的数据结构。我们这里只是打印退出信息:
|
|
的确,这就完成把 BPF 程序编译并安装到了内核中。取得了不错的进展 !
2.3 运行结果
为了运行 BPF 程序,我使用 sudo bpftrace --unsafe obpf.bt 1979820224 6666。
为了测试,我使用 netcat(nc)的 -p 参数选项指定源端口,如下所示:
|
|
运行结果如下:
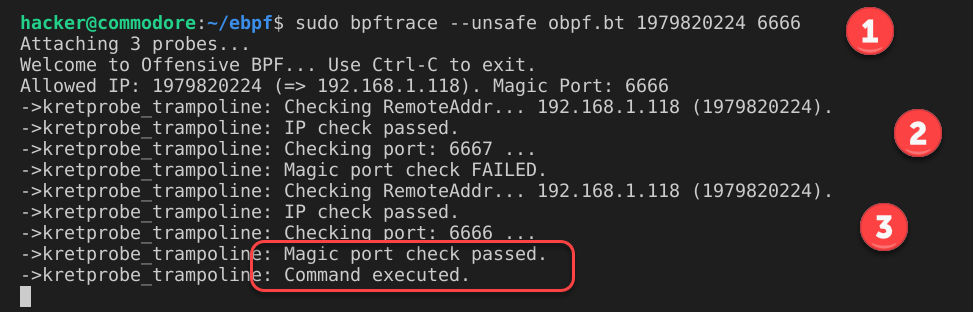
- 命令行的两个参数是允许的 IP 的整数和作为恶意触发器的神奇端口;
- 一次失败的尝试,正确的 IP 但错误的端口;
- 使用正确的 IP 和神奇的端口号成功地运行了后门程序;
最后,检查服务器上的输出文件 /tmp/o,我们可以看到文件确实被创建,结果是 `whoami 的输出:
|
|
看到该程序在服务器端运行,并最终触发了验证阶段的 BPF 程序,真是太让人兴奋了。这非常酷 !
现在有大量的功能可以在此基础上进行添加。
2.4 挑战
bpftrace 在功能还存一些局限:
- 例如,我找不到一个将 IP 地址转换为整数的函数。这就是为什么允许的 IP 的整数必须在命令行中提供,而不是作为容易阅读的 IP 地址。原因是(另一个限制),我找不到一种方法来比较
inet结构和string。 - 如前所述,读取远程端口并将其分配给一个变量有一些奇怪的地方,并显示出不一致的行为。如果能有内置的函数来读取 / 转换端口信息,那就太好了。
在我将用于红队行动的最终 BPF 程序中,我又增加了一些功能,以运行更多的命令,并通过安全的通道获取文件 – 目前这里并没有公布所有的功能。也许在未来,我会想出更多的有趣的功能呢,记着来查看后续的帖子。
3. 检测 BPF 滥用
蓝队有一套检测思路,目前我只从 bpftrace 的角度进行了探索,所以随着我对 eBPF 的学习和理解的加深,可能会有更多的建议。
3.1 搜集指标
获取有关 BPF 系统调用的数据对于深入了解其整体的使用情况至关重要。
3.2 检测加载的 BPF 程序
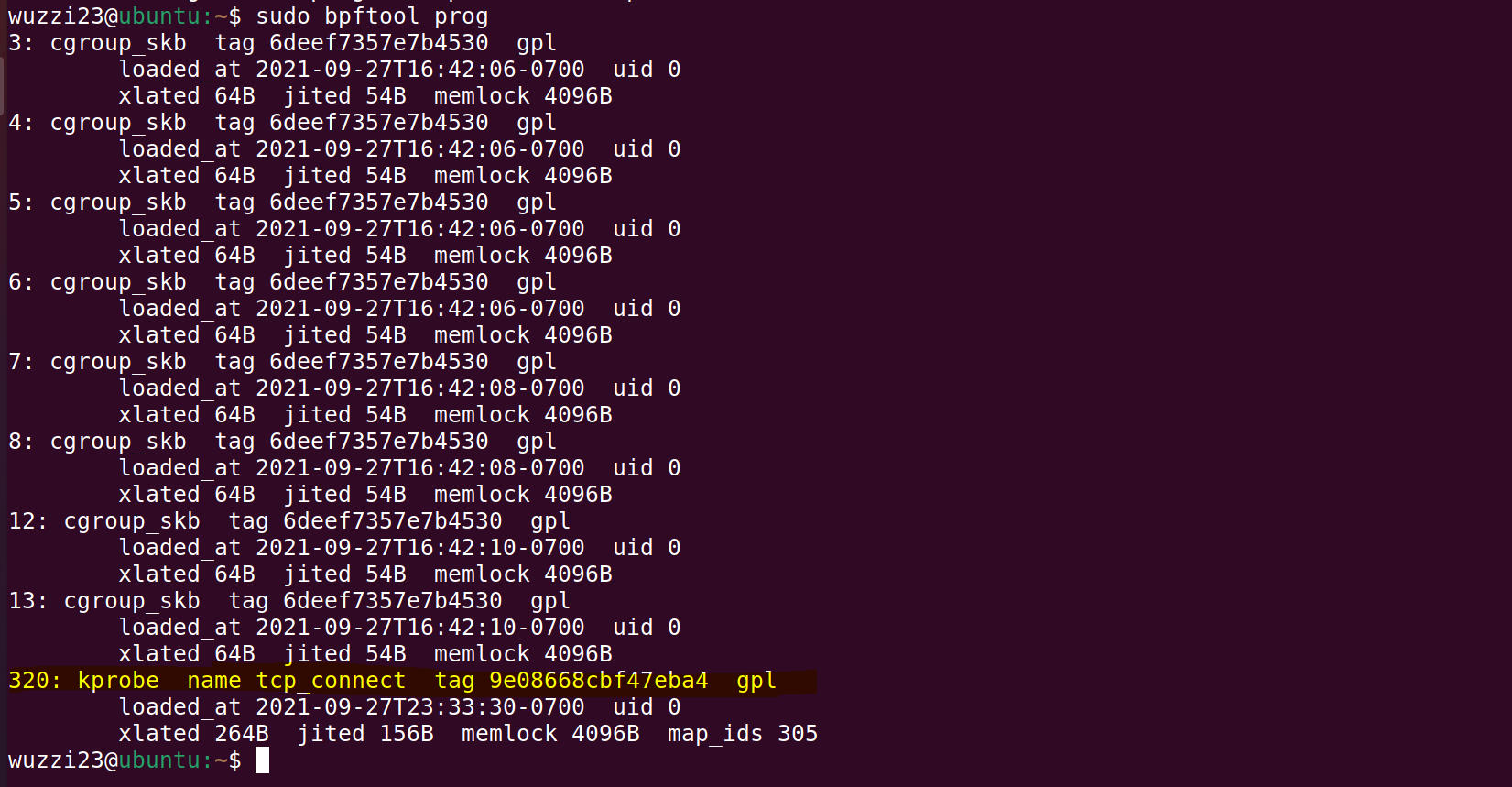
可通过 bpftool 工具来检查已加载的 BPF 程序。
例如,使用 bpftool prog 将展示加载 BPF 程序的详情:
3.3 bpftrace --unsafe 使用和 system() 调用
system() 调用的使用似乎很不寻常。因此,寻找包含 “bpftrace –unsafe " 的命令行参数似乎也是捕捉危险的bpf 程序的好方法。
3.4 持久化
请注意 ! BPF 程序在系统重启后并不会运行,所以攻击者会试图重启它们(cron jobs,等等)。
还有一种攻击途径可以将性能团队使用的或在主机上定期执行的现有程序后门。 我还没有看到任何签名验证方法,这可以帮助检测此类更改。
3.5 Hook BPF 系统调用本身 !
一个狡猾的攻击者可能会钩住 bpf() 系统调用本身来改变蓝队的实现 – 这是我想在未来的文章中探讨的问题。
4. 总结
希望本系列的第二篇文章,我更多地从技术角度来展示用处,并提供防御者需要开始的一些线索。
我认为 BPF 恶意软件在不远的将来会相当普遍,所以让我们需要在测试和检测方面领先一步。
在下一篇文章中,我想继续基于 bpftrace 探索,建立一个更复杂的、” 基于消息 " 的触发系统。源端口触发器并不是一个真正用于红队的解决方案 – 它对我来说更具有学习目的展示。
P.S.: 另外,在建立 / 测试新的 TTP 时,总是提醒要有适当的授权 - 不要做任何非法或有害的事情。
5. 资源
原文地址:https://embracethered.com/blog/posts/2021/offensive-bpf-bpftrace/
作者:wunderwuzzi
发布时间:2021 年 10 月 5 号
- 原文作者:DavidDi
- 原文链接:https://www.ebpf.top/post/offensive-bpf-bpftrace/
- 版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议. 进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。
- 最后更新时间:2022-11-05 21:36:52.142662417 +0800 CST

