揭秘 BPF map 前生今世
本文地址:https://www.ebpf.top/post/map_internal
1. 前言
众所周知,map 可用于内核 BPF 程序和用户应用程序之间实现双向的数据交换, 为 BPF 技术中的重要基础数据结构。
在 BPF 程序中可以通过声明 struct bpf_map_def 结构完成创建,这其实带给我们一种错觉,感觉这和普通的 C 语言变量没有区别,然而事实真的是这样的吗? 事情远没有这么简单,读完本文以后相信你会有更大的惊喜。
|
|
我们知道最终 BPF 程序是需要在内核中执行,但是 map 数据结构是用于用户空间和内核 BPF 程序双向的数据结构,那么问题来了:
-
通过
struct bpf_map_def定义的变量究竟是如何创建的,是在用户空间创建还是内核中直接创建的? -
如何实现创建后的 map 的结构,在用户空间与内核中 BPF 程序关联?你可能注意到在用户空间中对于 map 的访问是通过 map 文件句柄 fd 完成(类型为 int),但是在 BPF 程序中是通过
struct bpf_map *结构完成的。
毕竟数据交换跨越了用户空间和内核空间,本文将从深入浅出为各位看官揭开 map 整个生命管理的 “大瓜”。
2. 简单的使用样例
本样例来自于 samples/bpf/sockex1_user.c 和 sockex1_kern.c,略有修改和删除。
sockex1_user.c 用户空间程序主要内容如下(为方便展示,部分内容有删除和修改):
|
|
sockex1_user.c 文件中的 bpf_map_lookup_elem 调用的函数原型如下,定义在文件 tools/lib/bpf/bpf.c 中:
|
|
函数底层通过 sys_bpf(cmd=BPF_MAP_LOOKUP_ELEM,...) 实现,为我们方便 map 操作的用户空间封装函数, bpf 系统调用可参考 man 2 bpf。
其中 sockex1_kern.c 主要内容如下:
|
|
sockex1_kern.c 文件中的 bpf_map_lookup_elem 函数为内核中提供的 BPF 辅助函数,原型声明如下,详情可参考 man 7 bpf-helper:
|
|
用户空间与内核 BPF 辅助函数参数对比
通过分析 sockex1_user.c 和 sockex1_kern.c 函数中的 bpf_map_lookup_elem 使用姿势,这里我们做个简单对比:
|
|
那么如何将 int fd 与 struct bpf_map *map 共同关联一个对象呢? 这需要我们通过分析 BPF 字节码来进行解密。
3. 深入指令分析
首先我们将 sockex1_kern.c 文件使用 llvm/clang 将之编译成 ELF 的 BPF 字节码。对于生成的 sockex1_kern.o 文件可以用 llvm-objdump 来查看相对应的文件格式,这里我们仅关注 map 相关的部分。
3.1 查看 BPF 指令
|
|
上述结果展示了 BPF 程序中 socket1 部分的函数 bpf_prog1 的 BPF 指令,但是其中对于涉及到的变量 my_map 的引用都未有解决。上述的反汇编部分打印了 map_lookup_elem() 函数调用涉及的指令:
- 根据 BPF 程序调用的约定,寄存器
r1为函数调用的第 1 个参数,这里即bpf_map_lookup_elem(&my_map, &index)调用中的my_map。
|
|
上述 “7:” 行代表了为一条 16 个字节的 BPF 指令,表示加载一个 64 位立即数。
这里无需担心相关的 BPF 指令集,后续我们会详细展开解释。1 个 BPF 指令由 8 个字节组成,格式定义如下:
|
|
通过上述结构对应拆解一下 ”7:“ 行(其中包含了 2 条 BPF 指令,为 BPF 指令中的特殊指令,运行时会被解析成 1 条指令执行) ,第 1 条 BPF 指令详细的信息如下:(这里忽略了 off 字段)
opcode为 0x18,即BPF_LD | BPF_IMM | BPF_DW。该 opcode 表示要将一个 64 位的立即数加载到目标寄存器。dst_reg是 1(4 个 bit 位),代表寄存器r1。src_reg是 0(4 个 bit 位),表示立即数在指令内。imm为 0,因为my_map的值在生成 BPF 字节码的时候还未进行创建。
第 2 条指令主要负责保存 imm 的高 32 位。
3.2 加载器创建 map 对象
当加载器(loader)在加载 ELF 对象 sockex1_kern.o 时,其首先会从 ELF 格式的 maps 区域获取到定义的 map 对象 my_map 及相关的属性, 然后通过调用 bpf() 系统调用来创建 my_map 对象,如果创建成功,那么 bpf() 系统调用返回一个文件描述符 (map fd)。
同时,加载器也会对于基于 map 元信息(比如名称 my_map)与通过 bpf() 系统调用创建 map 后返回的 map fd 建立起对应关系,此后用户空间空间程序就可以使用 my_map 作为关键字获取到其对应的 fd,具体代码如下:
|
|
用户空间获取到了 map 对象的 fd,后续可用于 map_lookup_elem(map_fd, ...) 函数进行 map 的查询等操作。
3.3 第一次变身: map fd 替换
以上完成了 my_map 对象的创建,但是在 BPF 字节码程序加载到内核前,还需要将 map fd 在 BPF 指令集中完成第一次变身,如函数 lib/bpf.c: bpf_apply_relo_map() 的代码片段所示:
|
|
这里假设获取到的 map 文件描述符为 6,那么在加载的 BPF 程序完成 bpf_apply_relo_map 的替换后上述的指令对比如下:
ELF 文件中的字节码:
|
|
替换 map fd 后的字节码:
|
|
3.4 第二次变身: map fd 替换成 map 结构指针
当上述经过第一次变身的 BPF 字节码加载到内核后,还需要进行一次变身,才能真正在内核中工作,这次 BPF 验证器(verifier)扛过大旗。
验证器将加载器注入到指令中的 map fd 替换成内核中的 map 对象指针。调用堆栈的情况如下:
|
|
函数 replace_map_fd_with_map_ptr() 通过以下代码完成第二次大变身,实现了内核中 BPF 字节码的 imm 摇身一变成为 map ptr 地址。
|
|
于此同时,函数 convert_pseudo_ld_imm64() 还需要清理加载器设置的 src_reg = BPF_PSEUDO_MAP_FD 操作( prog->insns[insn_off].src_reg = BPF_PSEUDO_MAP_FD;), 用于表明完成了整个指令的重写工作:
|
|
如果这里的 my_map 在内核中 64 位地址为 0xffff8881384aa200,那么验证器完成第二次变身后的 BPF 字节码对比如下。
替换 map fd 后的字节码:
|
|
替换为 map 对象指针后的字节码如下:
|
|
在完成了上述两次变身后,当在内核中调用 map_lookup_elem() 时,第一个参数 my_map 的值为 0xffff8881384aa200,
从而实现了从最早的 ELF 中的 0 ,替换成了 map_fd (6),直到最后的 map 对象 struct bpf_map * (0xffff8881384aa200)。
提示,内核中 bpf_map_lookup_elem 辅助函数的原型定义为:
|
|
4. 整个流程总结
通过上述 map 访问指令的 2 次大变身,我们可以清晰了解 map 创建、map fd 指令重写和 map ptr 对象的重写,也能够彻底明白用户空间 map fd 与内核中 map 对象指针的关联关系。
俗话说一图胜千言,这里我们用一张图进行整个流程的总结:
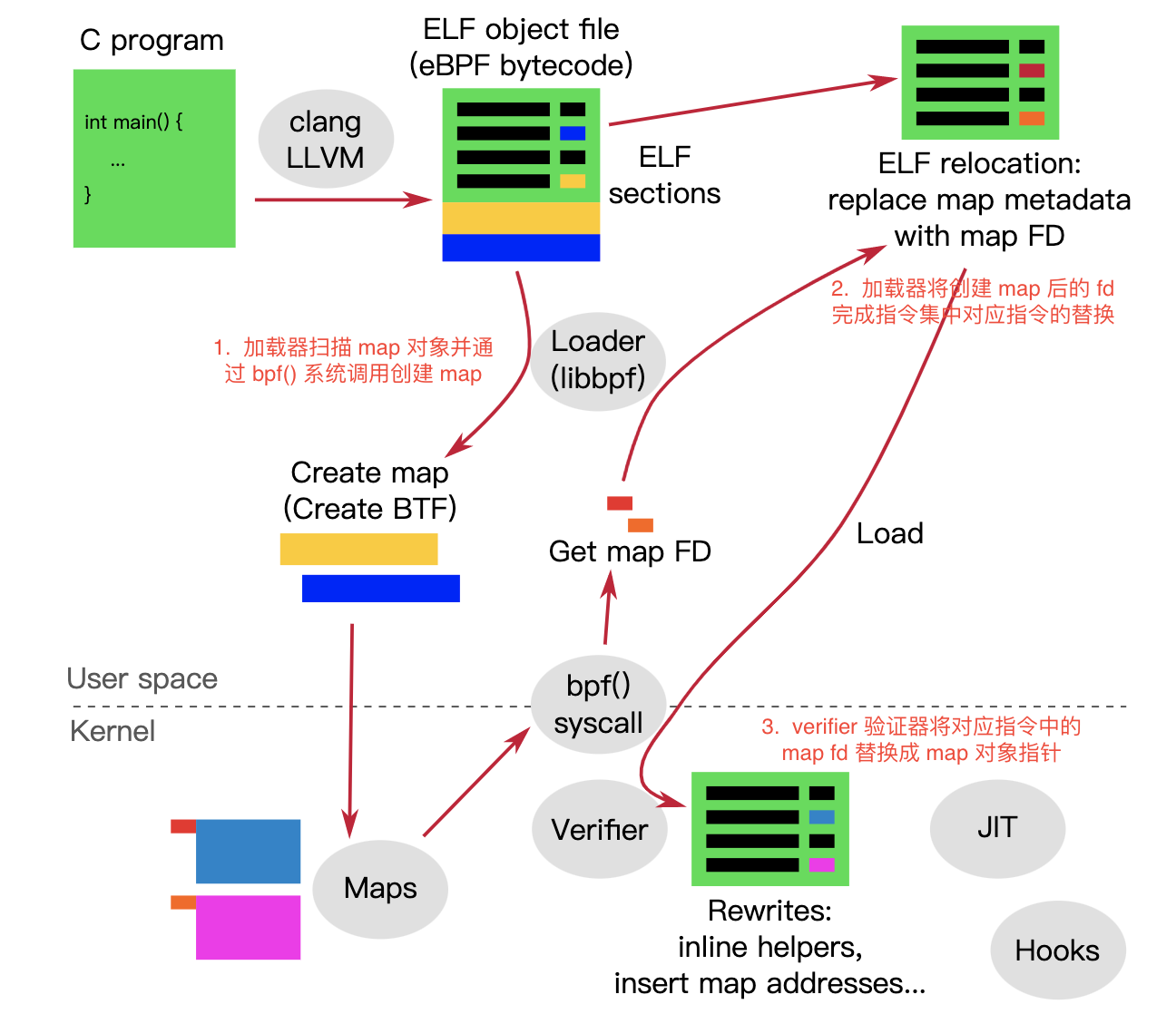
原始图片来自于这里 ,略有修改。
{kind=link}
参考
- 原文作者:DavidDi
- 原文链接:https://www.ebpf.top/post/map_internal/
- 版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议. 进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。
- 最后更新时间:2022-11-05 21:36:52.119667703 +0800 CST

