【BPF入门系列-9】文件打开记录结果跟踪篇
1. 前言
在上篇文章中我们为文件 open系统调用采用了 perf_event 的方式将数据从内核上报至用户程序。但是到目前为止,我们只是实现了文件打开记录的跟踪,并没有对文件访问的结果是成功还是失败进行展示。
与 kprobe 相对应的 kretprobe 实现可以帮助我们获取到 sys_open 函数的返回值。为了拿到 sys_open 系统调用的详细信息和返回结果,我们需要在 sys_open 函数入口时将文件访问相关信息进行保存,而在函数返回时读取函数入口保存的信息将返回结果与文件详情一起合并,将数据发送至用户程序。
kprobe 方式的实现是基于函数入口处的跟踪机制,而 kretprobe 跟踪机制则可以实现对于返回结果的跟踪。由于入口与返回跟踪是两种机制,需要在两个函数中实现。在函数入口跟踪函数中以 bpf_get_current_pid_tgid() 为 key,将入口相关数据信息保存在BPF 提供的 HASH 结构中,在函数返回以 bpf_get_current_pid_tgid() 为 key 读取入口相关信息与结果值合并,形成上报的完整数据 。
整个程序的大体实现结构如下图所示:
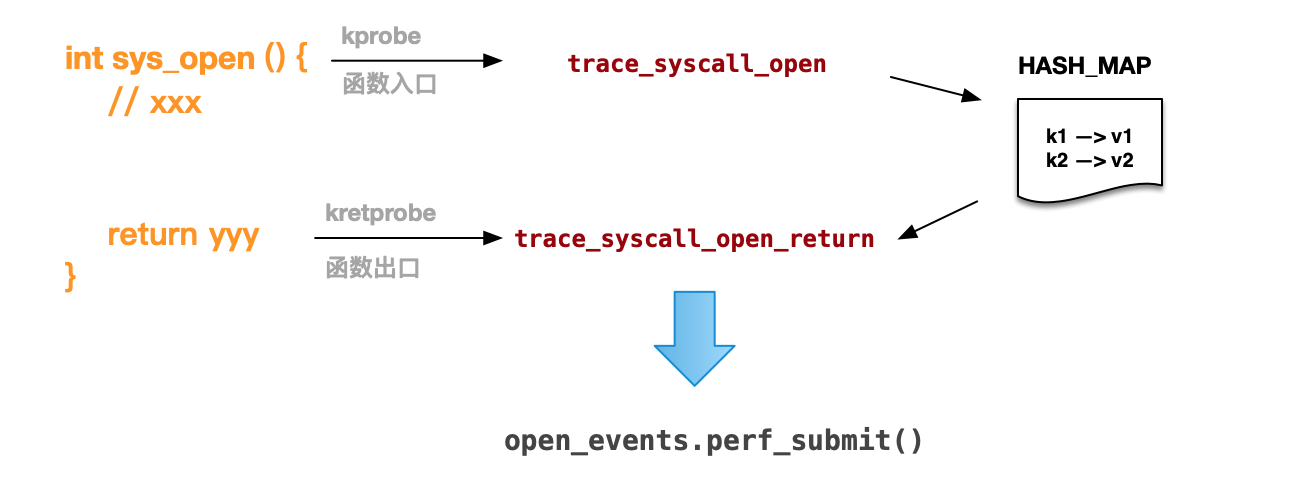
2. 代码实现
2.1 BPF 跟踪程序
在 BPF 跟踪程序中我们以下调整:
- 增加保存缓存结果数据格式,并定义中间结果保存的 HASH_MAP 结构,调整内核 BPF 跟踪程序与用户程序通信的数据格式,增加
ret和comm字段; - 调整跟踪函数的逻辑
trace_syscall_open,将入口处的详细信息发送至用作中间缓存的 HASH_MAP 结构中; - 新增加跟踪函数返回结果函数
trace_syscall_open_return,读取函数返回结果,并读取trace_syscall_open保存的入口相关信息合并后使用perf_submit函数发送数据;
prog 相关代码调整后如下:
|
|
对于代码的调整,这里我们详细进行解释:
-
主要增加功能对应的数据结构(或调整),并增加数据存储相关的定义。
- 我们为结构体
event_data_t增加了ret和comm两个字段分别用于保存sys_open系统调用函数的结果和调用的进程名称; - 新增定义新增的中间结果数据结构
struct val_t,主要包含id和fname两个字段,分别为pid_tgid和读取的文件名字; BPF_HASH(infotmp, u64, struct val_t);定义中间数据保存的 HASH_MAP,使用 BCC 宏定义,key 为 u64 类型,value 为struct val_t结构; map 结构为 BPF 程序重要的数据结构,可以在用户空间与内核空间同时访问,是通信的一种重要方式,除了 hash 类型还有 array 等多种数据类型;
- 我们为结构体
-
trace_syscall_open函数中的调整主要是将当前信息保存至HASH_MAP中,infotmp.update(&id, &val);以 id 为 key,将 val 对象结果保存至infotmp中; -
新增加函数
trace_syscall_open_return用于跟踪sys_open函数的结果;valp = infotmp.lookup(&id);用于读取在函数入口保存的信息,如果未查询到则直接返回,需要注意的是lookup函数的入参和出产都是指针类型,使用前需要判断;evt.ret = PT_REGS_RC(ctx);主要是使用宏PT_REGS_RC从 ctx 字段中读取本次函数跟踪的返回值;bpf_get_current_comm(&evt.comm, sizeof(evt.comm));使用函数bpf_get_current_comm读取当前进程的 commandline 并保存至对应字段中evt.comm;- 在完成正常结果获取并将数据发送以后,需要清理当前的记录,调用
infotmp.delete(&id);实现;
至此,BPF 程序的调整已经完成,由于我们新增了 kretprobe 方式跟踪,因此需要在用户空间增加对应的关联动作。
2.2 用户空间程序
|
|
用户空间程序的调整相对比较少,增加 kretprobe 跟踪,并在事件跟踪函数中打印出我们新增加的对应字段:
b.attach_kretprobe函数将将sys_open函数的结果跟踪与函数trace_syscall_open_return完成关联;- 我们在
print_event函数中增加新增结构体字段comm和ret的打印;
函数运行的结果如下:
|
|
完整代码可以参见 open_perf_output_ret.py。
3. 总结
支持我们通过 3 篇文章介绍了如何在 BPF 技术中使用 kprobe 技术跟踪 open 系统调用,并展示了如何使用 perf_event 的方式进行数据通信;最后我们使用 kretprobe 技术实现了 open 系统调用的返回值,并使用 BPF 技术中实现的 HASH_MAP 保存中间临时结果,并在 kretprobe对应的跟踪函数中将函数入口信息与结果值合并传递值用户空间。
基于上述案例,我们可以很容易扩展到其他相关的系统调用,并通过功能增强实现我们自己的 BPF 跟踪程序。
相关阅读:
- 原文作者:DavidDi
- 原文链接:https://www.ebpf.top/post/ebpf_trace_file_return/
- 版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议. 进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。
- 最后更新时间:2022-11-05 21:36:52.02807729 +0800 CST

