BTF:实践指南
本文地址:https://www.ebpf.top/post/btf-bpf-type-format
BPF 是 Linux 内核中基于寄存器的虚拟机,可安全、高效和事件驱动的方式执行加载至内核的字节码。与内核模块不同,BPF 程序经过验证以确保它们终止并且不包含任何可能锁定内核的循环。BPF 程序允许调用的内核函数也受到限制,以确保最大的安全性以防止非法的访问。
尽管 BPF 为编写事件驱动的内核空间代码提供了一种有效的解决方案,但开发人员的体验仍无法与其他编程语言或框架相提并论。BPF 开发的两个最重要的问题是缺乏简单的调试和可移植性。
为了缓解这些问题,我们转向 BTF。BTF 是针对 BPF 程序的类型信息进行编码文件格式,通过 BPF 程序的类型信息进行编码,为程序提供更好的内省(introspection)和可见性。本文我们将介绍 BPF 的典型局限性以及如何使用 BTF 来克服。
请注意,本文使用术语 BPF 来表示 eBPF(扩展的 Berkeley 数据包过滤器),eBPF 扩展 “ 经典 ” cBPF。
1. BPF 的常见限制
在 BPF 程序的开发和运行过程中,我们会经常会面临调试限制和可移植性问题,如前所述。
1.1 调试限制
几乎所有现代编程语言都有对应的调试器,通过调试器可以帮助我们更好了解正在运行的程序。例如,GDB 是 C 和 C++ 的常用调试器,除其他外,基于 GDB 我们可以打印正在运行的程序中的变量值。

图 GDB 变量打印
但是很不幸,BPF 程序并没有类似的这样的工具。尽管检查数据只是调试的一小部分,但为 BPF 实现类似的结果可以为未来的广泛调试工具打开一扇门。为了实现这一点,BPF 需要知道关于程序的相关的部分元数据。
这类关于类型信息的元数据,正是 BTF 封装的内容。
1.2 可移植性
BPF 程序在内核空间中运行,可以访问内部内核状态和数据结构。但是,并没有办法保证内核数据结构和类型在不同内核版本是相同的,甚至相同内核版本的不同机器之间也可能不同(这可能取决于内核编译选项)。这意味着在一台机器上编译的 BPF 程序并不能保证在另一台机器上正确运行。
假设 BPF 程序正在从内核结构中读取一个字段,该字段位于距结构开头的偏移量 8 处。现在在更高版本的内核中,在该变量之前添加了其他字段,导致访问的字段的偏移量变成了 24,这会导致 BPF 程序在偏移量 8 读取的数据可能为垃圾数据。类似情况,也可能会发生某些字段最终得到在后续内核版本中的重命名。例如,在内核版本 4.6 和 4.7 之间,thread_struct 的 fs 字段可能会重命名为 fsbase 。最后,还可能是因为配置禁用了某些功能并编译了部分结构,导致可能 BPF 程序在不同的内核配置上运行。
所有上述这些场景的存在,意味着你不能在当前机器上编译 BPF 程序并将二进制文件分发到其他系统。
一个标准的解决方案是使用 BPF Compiler Collection (BCC)。使用 BCC,你通常将 BPF 程序作为纯字符串嵌入到用户空间程序(例如,Python 程序)中。在目标机器上执行期间,BCC 使用其嵌入式 Clang/LLVM 组合并使用本地安装的内核头文件动态编译程序。
然而,这种方法引入了更多问题。首先,Clang/LLVM 组合非常庞大,将其嵌入到应用程序中会导致二进制文件大小过大。它还占用大量资源,并且会在编译期间耗尽大量资源。最后,这种方法需要在目标机器上安装内核头文件,但情况可能并非总是如此。
解决方案是 BPF CO-RE(一次编译 —— 随处运行)。使用 BTF,我们可以消除在目标机器上安装内核头文件或将 Clang/LLVM 嵌入应用程序并在目标机器上编译的需要。
2. BTF 是什么?
如前所述,BTF 是编码 BPF 程序和 map 结构等相关的调试信息的元数据格式。BTF 可以将元数据数据类型、函数信息和行信息编码成一种紧凑的格式。
在非 BPF 程序中,这些元数据通常使用 DWARF 格式存储。但是,DWARF 格式的实现还是相当复杂和冗长,并且由于其在大小方面的开销,使其不适合包含在内核中。而 BTF 是一种紧凑而简单的格式,让其可以包含在内核镜像中。
BTF 使用少数类型描述 符之一表示每种数据类型:
- BTF_KIND_INT
- BTF_KIND_PTR
- BTF_KIND_ARRAY
- BTF_KIND_STRUCT
- 等等
类型信息存储在生成的 ELF 的 .BTF 部分中。除了类型描述符之外,此部分还对字符串进行编码。函数和行信息存储在 .BTF.ext 部分中。
关于 BTF 的详细说明,可以查看 Linux Kernel 文档。
3. BTF 快速入门
3.1 BPF 快速入门
现在让我们通过使用 BTF 漂亮地打印 BPF map 的教程进行更多实践,从而显著改进调试。
要开始,我们需要在启用 CONFIG_DEBUG_INFO_BTF 选项的情况下编译 Linux 内核。大多数发行版都启用了此选项,但你可以通过运行以下命令进行检查:
|
|
当然,我们还需要在计算机上安装 Clang 和 LLVM。
由于我们需要将编写 XDP 程序来处理网络设备上的数据包,因此创建一个虚拟网络接口 是个好主意,这样就不会最终失去物理接口中的互联网连接。设置虚拟接口的最简单方法是使用此 repo。
克隆 repo 并设置一个名为 test1 的虚拟接口:
|
|
现在编写一个 BPF 程序来计算接口上接收到的 IPv4 和 IPv6 数据包的数量。文件 xdp_count.c 的文件内容如下:
|
|
在前面的代码中,名为 cnt 的 BPF map 存储数据包的数量。cnt 是两个元素的数组。IPv6 数据包的数量存储在 key 0 中,IPv4 数据包的数量存储在 key 1 中。
使用 Clang 编译代码:
|
|
接下来,使用 bpftool 加载程序:
|
|
运行以下命令并记下我们刚加载的程序的 ID 和程序正在使用的 map 的 ID:
|
|
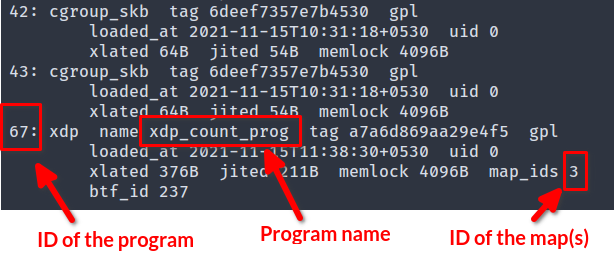
图 bpftool prog 列表的输出
我们还可以通过运行 sudo bpftool map list 来获取 map ID。
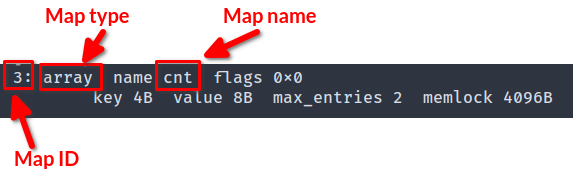
图 bpftool map list 的内容输出
此命令为我们提供 map 的名称、类型、键大小、值大小和最大条目数。
现在,将 BPF 程序附加到网络设备。
|
|
将 program_id 替换为程序的 ID,并将 device_name 替换为程序附加到的网络设备的名称(例如 enp34s0)。
现在,向该设备发送一些数据包。测试环境脚本已经提供了一个方便的 ping 命令来执行此操作:
|
|
打印 map 并检查处理的数据包情况:
|
|

图 map 的打印值
如图所示,map 中有两个预期的元素。这些值采用十六进制格式,并且还取决于运行机器的字节顺序。在截图中,它是小端格式,这意味着已经处理了 22 个 IPv6 和 4 个 IPv4 数据包。
很明显,结果是十六进制的,小端格式,一看就不好调试。因此,我们需要使用 BTF 对 map 进行注释,以便更好地展示。
如下更改 cnt 的声明并将新代码保存在 xdp_count_btf.c 中 -
|
|
请注意,部分名称现在为 .maps,并且地图本身已使用启用 BTF 的宏 __uint 和 __type 进行了注释。
使用 Clang 编译代码:
|
|
使用 -g 标志将创建调试信息并生成 BTF。请注意,之前也使用了 -g 标志,因为 libbpf需要它 来加载程序;然而,以前 map 没有被 BTF 注释,所以 bpftool 不能够优雅地进行打印。
验证 BTF 部分是否存在于生成的目标文件中。
|
|
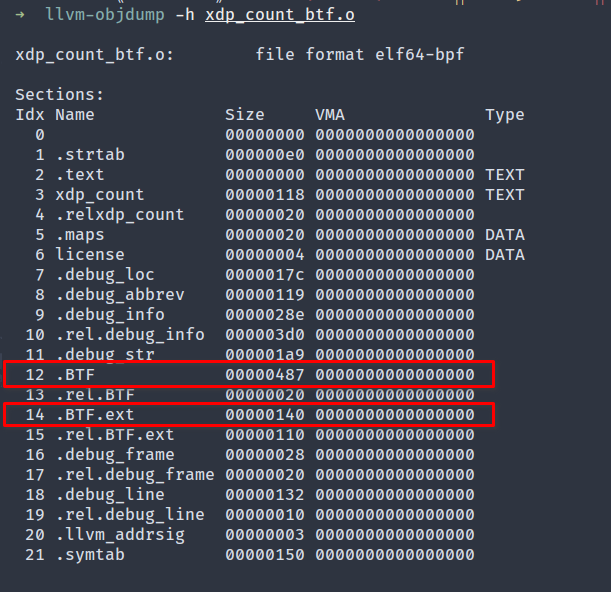
图 llvm-objdump 的输出
如前所述,.BTF 部分包含类型和字符串数据,.BTF.ext 部分对 func_info 和 line_info 数据进行编码。
首先,卸载前面的 BPF 程序。
|
|
然后按照类似的过程加载新程序并将其附加到接口,然后对接口发送一些数据:
|
|
最后,打印新程序对应的 map 。如果一切顺利,这一次的输出会有很大的不同。
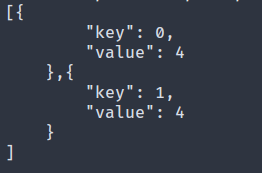
图 map 的结构的打印值
它不仅以 JSON 格式打印得很漂亮,而且值也是十进制的,使其更具可读性和易懂性。
3.1 BTF 和 CO-RE
如前所述,BTF 可以启用 CO-RE 使 BPF 程序可移植到不同的内核版本或用户配置。我们也可以通过生成内核本身的 BTF 信息来消除对本地内核头文件的需求:
|
|
上述命令将创建一个巨大的 vmlinux.h 文件,其中包含所有内核类型,包括作为 UAPI 的一部分公开的类型、内部类型和通过 kernel-devel 可用的类型,以及一些其他地方不可用的更多内部类型。在 BPF 程序中,我们可以只 #include "vmlinux.h" 并删除其他内核头文件,如 <linux/fs.h>、<linux/sched.h>等。
摆脱内核头文件依赖性只是 BTF 可以实现的目标的冰山一角。如需 BTF 和 CO-RE 的详尽解释,可以阅读这篇文章。
4. 结论
BTF 是一个非常强大的工具,可以使 BPF 程序更易于调试和移植。由于它是一项相对较新的技术,因此开发仍在进行中,你可以期待在未来看到大量改进。
本文让你大致了解 BTF 可以实现什么。你可能已经了解了 BPF 的缺点、BPF 是什么以及如何使用 BTF 注解 map 和打印 map 结构。最后,你还了解了 BTF 如何充当通过 CO-RE 增强可移植性的起点。
原文地址:https://www.containiq.com/post/btf-bpf-type-format
作者:Aniket Bhattacharyea
时间: July 13, 2022
- 原文作者:DavidDi
- 原文链接:https://www.ebpf.top/post/btf-bpf-type-format/
- 版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议. 进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。
- 最后更新时间:2023-05-06 08:34:16.968188394 +0800 CST

