【译】神奇的 eBPF
本文地址:https://www.ebpf.top/post/awesome-ebpf
原文地址:https://filipnikolovski.com/posts/ebpf/
发布时间: 2020.11.20 19:05
1. 前言
当在工作中对微服务的跟踪和可观察性进行研究时,我发现了 Pixielabs 工具。该工具宣称可在不需要任何装置或应用程序内的特殊代码的情况下,你可立即对应用程序进行故障排查,这对于我来说听起来很神奇 ✨。因此,我很自然地想更多了解是什么样的技术能够发挥如此的作用,在滚动浏览该网站后,在 " 无装置 " 部分中,我发现了 eBPF 的缩写。
在网上进行了进一步的挖掘,阅读了最初的设计论文并观看了几个视频后,eBPF 这项技术引起了我的注意,所以我想写一些关于 eBPF 的笔记,当然,我也希望这篇文章也能够引发你对 eBPF 的兴趣。
2. eBPF 究竟是什么?
TL;DR 版本是,这项技术可使用户应用程序能够在 Linux 内核本身中通过沙盒环境运行。在某种程度上,eBPF 使内核变得可编程,从而可释放出巨大的可能性(译者注:比如用户程序定义内核)。
你可以从内核中选取任何函数(译者注:并非全部,部分调用的函数明确禁止了 eBPF 跟踪),并在每次函数执行时运行 eBPF 程序。可运行一个 “附着” 于网络套接字、追踪点和 perf 事件的程序,这在很多场景下非常有用。开发者可对内核进行调试,而无需重新进行编译,诸如以下场景:
- 应用程序性能和故障排查
- 网络和安全
- 运行时安全
- 应用跟踪
- 可观察性
这就是 Pixie 工具能够进行黑盒分析的原因,而且这的确不需要在需要调试的应用程序中进行任何修改。
最初,BPF 是设计用于捕获和过滤符合特定规则的网络数据包,并在内核层面丢弃任何不需要的数据包。这就是为什么它被称为 “伯克利包过滤器” 的原因。如你曾经使用过 tcpdump,那么你可能已经使用过 BPF 技术了。现在,eBPF 可以应用于数据包过滤外的许多场景,但由于某种原因,BPF 这个名字被坚持了下来。
这种网络监控架构在性能上大大优于当时现有的数据包捕获技术,这主要是因为过滤工作在内核中完成,避免了复制所有数据包至用户空间进行过滤和计算。但随着处理器的进步,BPF 的初始设计变得有些局限。扩展的 BPF(eBPF)设计的引入,就是为了更好利用现代的处理器的能力。
最初,eBPF 也被用作网络包过滤解决方案,但事实证明,在内核内运行用户空间程序的能力被证明是非常强大的。新设计扩展了 BPF 虚拟机的功能,使其不仅仅再是在数据包上进行过滤动作,具有在所有类型的事件上运行特定动作的能力。
3. eBPF 是如何工作的?
一个 eBPF 程序只是一个 64 位指令的序列。虚拟机的指令集是相当有限的,主要考虑两个目标:
- 代码需要尽可能快地被执行。
- 所有的 BPF 指令在加载时必须是可验证的,以确保内核的安全。
所以,eBPF 代码是在内核内的安全虚拟机中运行的。可使用框架(如 bcc 和 bpftrace)来完成程序编写,然后将程序字节码通过 bpf 系统调用加载至内核。
为了消除在内核中运行用户空间程序时的安全性和稳定性风险,需要执行多项检查以确保运行的代码的安全性,并且需要保证它会终止而不会导致系统死机。
首先,为了能够运行加载 eBPF 代码的用户程序,它的运行需要 root 权限,除非启用了非特权 eBPF(在这种情况下,进程可以加载缩减功能的程序)。其次,所有 eBPF 程序都必须经过 eBPF 验证器才能执行。
验证器为了保护内核会对加载的代码进行检查。第一个检查确保任何可能冻结内核的无界循环被禁止。第二个是更加广泛的检查,通过模拟代码的执行,确保代码的所有路径都运行完成,而且没有越界的内存被访问,并且总体上虚拟机的状态是有效的。
验证过程的最后一步涉及限制 eBPF 程序的能力,比如哪些内核函数可以调用(译者注:这里内核函数为 eBPF 的辅助函数,直接调用内核的函数的能力当前只是特定的 tcp 拥塞相关的内核函数),哪些数据可以访问。通过程序类型,验证器就可知道如何应用这些限制。当我们将程序与某个事件联系起来时,程序类型是确定的。
在验证过程完成后,BPF 字节码就会被解释,或者被 JIT 编译器编译成本地指令,每当内核中发生事件时就会高效地运行。
4. kprobes & uprobes
我们可以创建和插入内核探针(或简称 kprobes)至内核中的几乎任何函数,并附加一个 eBPF 程序,以便在每次函数时执行 eBPF 程序。
这里有一个简单的 hello world 例子,来自 bcc 仓库:
|
|
这里,eBPF 程序是用伪 C 代码编写的,其作为一个字符串放在变量 prog 中。bcc 框架协助完成了生成字节码、加载程序等所有繁重的工作,这使得编写程序更容易一些。
在这个例子中,hello 函数调用了一个叫 bpf_trace_printk 的 bpf 辅助函数,它输出了一个 “Hello, World!” 的跟踪。然后我们加载程序,并为 clone 事件附加一个内核探针,基本上说我们想在每次 clone 被调用时就会调用 hello 程序。
之后,脚本会等待新的跟踪,然后获取字段并将数值打印到屏幕上。
我们尝试着运行脚本程序:
|
|
脚本程序已经成功地加载了 eBPF 程序,现在我们则需要等待着跟踪事件的到来。接下来要做的事情是尝试调用 clone 系统调用。我们可以在终端上运行任何命令,例如 ls,其就会创建一个子进程。由于有火狐浏览器在运行,它在此期间创建了一些子进程,于是跟踪开始出现了:
|
|
正如我们所看到的,“Hello, World!” 与其他跟踪字段一起被打印在屏幕上。这超级酷!
除了附加到内核函数,我们还可以观察在用户空间调用的函数,比如 malloc 或 strlen。这可以通过另一个 Linux 内核的特性 –uprobes 来实现。
这里有一个有趣的脚本,它通过追踪 strlen() 来计算字符串的频率,并使用一个哈希 map 来存储字符串以及重复出现的次数:https://github.com/iovisor/bcc/blob/master/examples/tracing/strlen_count.py
5. 辅助函数
由于 eBPF 程序禁止调用任意内核函数,因此内核为我们提供了辅助函数,例如 bpf_trace_printk 函数。我们可以使用它们来:
- 获取当前时间
- 与 eBPF map 交互
- 操纵网络数据包
- 打印调试信息
请注意,每个程序只能使用辅助函数的一个子集,因为程序可能在不同的上下文中运行。下面是 BPF 辅助函数的列表。
6. map 存储
要编写更复杂的程序,你将需要某种类型的数据存储,这就是 map 的作用。它们是 BPF 内部系统的一个重要部分,其允许程序存储信息,且这些信息可从用户空间进行访问。
BPF 支持不同类型 的数据存储 – 你可以使用哈希 map,数组(array),甚至是栈(stack)或队列(queue),当然这取决于程序使用场景。
7. 总结
eBPF 为可观察性提供了各种可能性。你可以把一个系统当作一个黑盒子(不需要真正了解实现逻辑),就可以运行各种有趣的分析:统计最频繁调用的函数,跟踪网络数据包,性能跟踪和调试等等。
有无数的工具可以用来观察系统的每一个组成部分:CPU、内存、文件系统、网络、容器、应用程序 ……
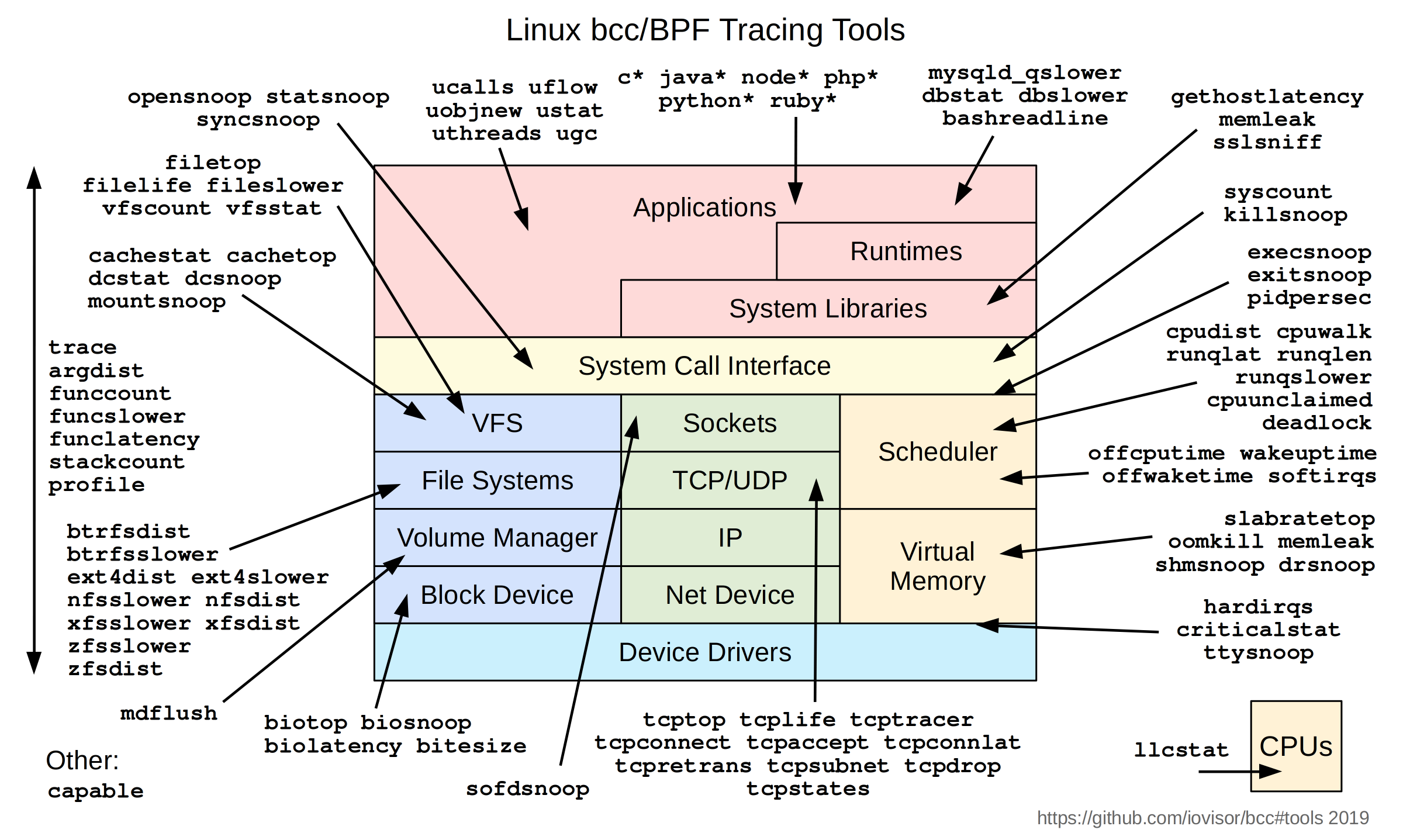 BCC 性能工具(由 Brendan Gregg 提供 )
BCC 性能工具(由 Brendan Gregg 提供 )
我只是触及了 eBPF 主题的皮毛,迫不及待地想了解更多以及通用的 Linux 性能。关于这项令人兴奋的技术,有大量精彩的帖子和视频,我在下面给出了一些链接。干杯 !
8. 参考
- https://www.tcpdump.org/papers/bpf-usenix93.pdf – BPF paper
- https://lwn.net/Articles/740157/ – A thorough introduction to eBPF
- https://www.youtube.com/watch?v=16slh29iN1g – interesting talk by Brendan Gregg on BPF performance analysis at Netflix
- http://www.brendangregg.com/ebpf.html – eBPF trace tools
- https://github.com/iovisor/bcc/blob/master/docs/reference_guide.md – BCC reference guide
- 原文作者:DavidDi
- 原文链接:https://www.ebpf.top/post/awesome-ebpf/
- 版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议. 进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。
- 最后更新时间:2022-11-05 21:36:51.843312439 +0800 CST

