【BPF入门系列-6】BPF 环形缓冲区
译者:范彬 原文地址:BPF ring buffer
当前 perf 缓冲区已成为从内核向用户空间发送数据的标准。BPF 环形缓冲区是一个新的BPF数据结构,解决了 BPF perf 缓冲区内存效率和事件重新排序的问题,同时性能达到或超过了 perf 缓冲区。 它既提供了与 perfbuf 兼容的功能,可轻松进行移植,又提供了具有更好可用性的新的 reserve / commit API。 综合基准和实际基准均表明,几乎所有情况下都应考虑将 BPF 环形缓冲区作为从 BPF 程序向用户空间发送数据的默认选择。
BPF 环形缓冲区对比 BPF perf 缓冲区
如今,每当 BPF 程序需要将收集的数据发送到用户空间进行处理和日志时,通常都会使用BPF perf 缓冲区(perfbuf)。 Perfbuf 是每个 CPU 环形缓冲区的集合,它允许内核和用户空间之间高效地交换数据。它在实践中效果很好,但是由于 perfbuf 是基于 CPU 的设计,事实证明很不方便。它在实践中存在两个主要缺点:内存使用效率低和事件重新排序。
为了解决这些问题,从Linux 5.8开始,BPF提供了新的BPF数据结构(BPF映射):BPF环形缓冲区(ringbuf)。 它是一个多生产者单消费者(MPSC)队列,可以同时在多个CPU之间安全地共享。
BPF ringbuf 支持 BPF perfbuf 常见功能:
-
可变长度数据记录;
-
能够通过内存映射区域从用户空间有效读取数据,无需额外的内核的内存复制和系统调用;
-
支持epoll通知,并且为了绝对最小的延迟,进行忙循环。
同时,BPF ringbuf 解决了以下 BPF perfbuf 的问题:
-
内存开销;
-
数据排序;
-
浪费的工作和额外的数据复制。
内存开销
BPF perfbuf 为每个 CPU 分配一个单独的缓冲区。这通常意味着 BPF 开发人员必须做出权衡:或是分配足够大的单 CPU 缓冲区以适应发送数据的峰值。或是提高内存效率,对于稳定状态下大多数是空缓冲区的情况下不浪费不必要内存,而是在数据峰值期间丢弃数据。对于那些在大部分时间都处于空闲状态但在短时间内周期性地涌入大量事件的应用程序,尤其棘手,很难找到合适的平衡点,因此 BPF 应用程序通常要么出于安全考虑过度分配 perfbuf 内存,要么会不时遇到不可避免的数据丢失。
与 BPF perfbuf 相比,BPF ringbuf 是所有 CPU 共享缓冲区,允许使用一个大公共缓冲区。更大的缓冲区不但可以达到更大的数据峰值,而且允许总体上使用更少的RAM。随着CPU数量的增加,BPF ringbuf 对内存的使用也可以更好地扩展,这意味着从16核CPU到32核CPU并不一定需要两倍的缓冲区来容纳更多的负载。不幸地是,使用BPF perfbuf,由于是每个CPU的缓冲区,在此问题上你将别无选择。
事件排序
如果 BPF 应用程序要跟踪相关事件,例如:进程开始和退出,网络连接生命周期事件等,事件的正确排序至关重要。对于 BPF perfbuf,事件排序是有问题的。如果相关事件数毫秒内在不同的CPU上连续发生,则它们可能会无序发送。这也是由于 BPF perfbuf 是单 CPU 的特性所致。
作为一个真实的例子,几年前我写的一个应用程序跟踪进程 fork/exec/exit 事件,并收集每个进程的资源使用情况统计信息。我的应用程序必须将每个事件发送到BPF perfbuf中,但是很多时候它们都是乱序到达的。这是因为由于内核调度程序将fork(),exec() 和exit() 从一个CPU调度到另一个CPU,所以它们可以在不同的CPU上以非常快速地顺序连续发生。要解决这一问题,就需要大幅增加应用程序处理逻辑的复杂性,而问题地本质非常简单,这远远超出了人们的预期。
如果使用 BPF ringbuf,这将根本不是问题。BPF ringbuf 通过将事件发送到共享缓冲区中来解决此问题,并保证如果事件 A 在事件 B 之前提交,那么事件 A 也将在事件 B 之前被处理。这通常会很明显简化处理逻辑。
浪费的工作和多余的数据复制
使用 BPF perfbuf,BPF 程序要准备一个数据样本,然后再将其复制到 perf 缓冲区中以发送到用户空间。这意味着相同的数据必须被复制两次:首先复制到局部变量,或对于不能容纳在小 BPF 堆栈中的大样本,将其复制到每个 CPU 数组中,然后复制到 perfbuf 中。更糟糕的是,如果发现 perfbuf 剩余的空间不足,那么所有这些工作都将浪费掉。
BPF ringbuf 支持一种替代的预留/提交API来避免这种情况。可以先预留数据空间。如果预留成功,则 BPF 程序可以直接使用该内存来准备一个数据样本。这样提交数据发送到用户空间是一个非常高效的操作,不可能失败,也完全不会执行任何额外的内存副本。如果由于缓冲区空间不足而导致预留失败,那么至少在记录数据完成所有工作,数据丢弃掉之前,就可以知道这一点。下面 ringbuf-reserve-commit 示例将演示实际使用情况。
性能和适用性
在所有实际应用中,BPF ringbuf 的性能均优于BPF perfbuf(特别是考虑到 BCC/libbpf处理 perfbuf 数据的默认设置有所欠佳)。具体数字,你可以在这个补丁中找到各种情景大致的综合基准测试结果。
理论上,当每秒数百万个事件时,由于BPF perfbuf是每个CPU的缓冲区,可以支持更高的数据吞吐量。但是实验证实,通过编写实际的高吞吐量程序,如果类似于 BPF perfbuf,将 BPF ringbuf 设为每个CPU缓冲区,BPF ringbuf 仍然是 BPF perfbuf 的更高性能替代品。特别是如果使用手工数据可用性通知。你可以在内核自测集中查看基本的multi-ringbuf示例(包括BPF侧,用户空间)。稍后,我们将演示一个手工控制数据可用性通知示例。
唯一情况,当 BPF 程序必须从不可屏蔽中断(NMI) 上下文中运行时,例如: 处理 perf 事件的cpu-cycles,你可能需要特别小心,先进行实验。 BPF ringbuf 在内部使用了非常轻量级的自旋锁,这意味着如果在 NMI 上下文中争用锁,则数据预留可能会失败。因此,在NMI上下文中,如果 CPU 竞争很高,即使 ringbuf 本身获得一些可用空间,一些数据也可能会丢失。
在其他情况下,选择新的数据结构 BPF ringbuf 是一个非常明显的选择。 BPF ringbuf 可提供更好的性能和内存效率,更好的排序保证,以及在内核侧和用户空间中更好的 API。
示例代码
为了演示 BPF ringbuf API,将 BPF ringbuf API 与 BPF perfbuf API 进行比较,并了解它们在实践中的典型用法,我编写了一个小bpf-ringbuf-examples项目。我们将在本文介绍该项目。
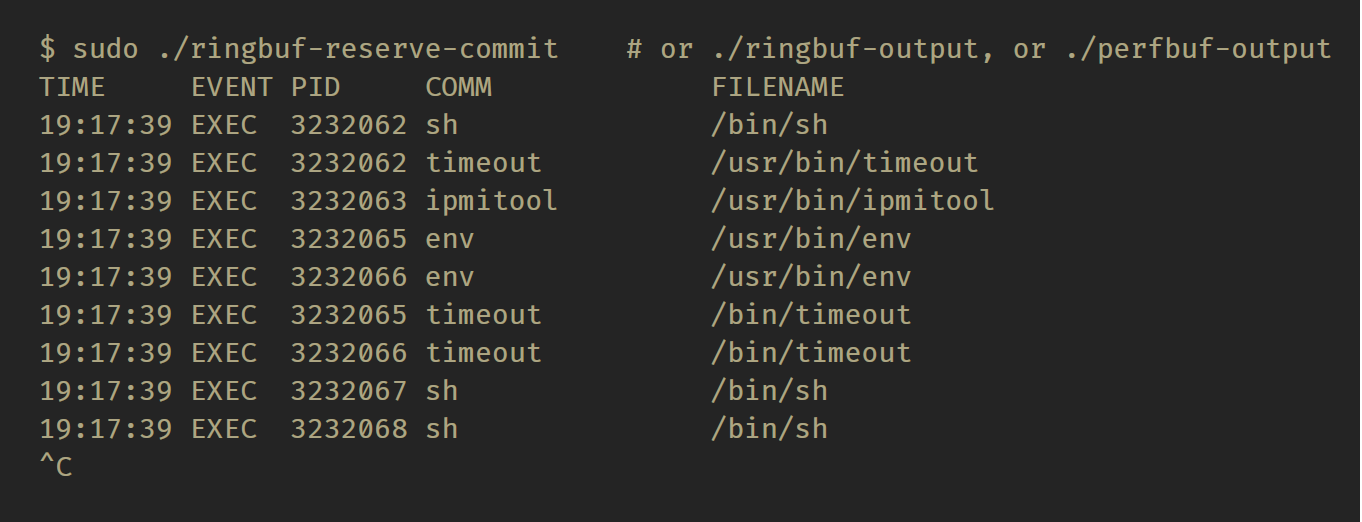
该项目是基于同一BPF程序实现了三个示例,该程序将跟踪新进程产生的所有execs进程。 对于每个系统调用函数exec(),进程ID(pid),进程名称(comm)和可执行文件路径(filename)被捕获到一个样本中,并发送到用户空间进行处理。这里,我们仅是调用printf(),将所有内容打印到标准输出中。三个示例的输出如下图所示(记住要使用sudo运行示例):
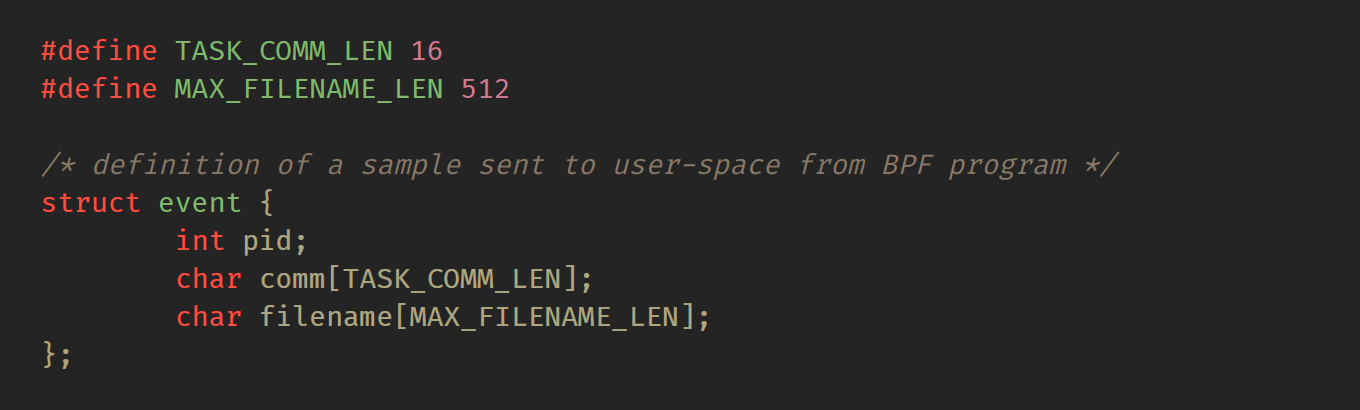
下面是样本数据的C结构定义。此数据结构用于BPF程序发送的数据,同时用于程序的用户空间部分使用。
BPF perfbuf: bpf_perf_event_output()
让我们从一个BPF perfbuf 示例开始,我们可以在这里找到示例中部分BPF代码。
首先,头文件包括内核的<linux / bpf.h>有一些基本 BPF 定义,libbpf <bpf / bpf_helpers.h>定义了BPF帮助器。“ common.h”定义了应用程序类型,该程序类型可在BPF程序和用户空间程序代码之间共享。这里,我们还指定程序遵循GPL-2.0/BSD-3双重许可:
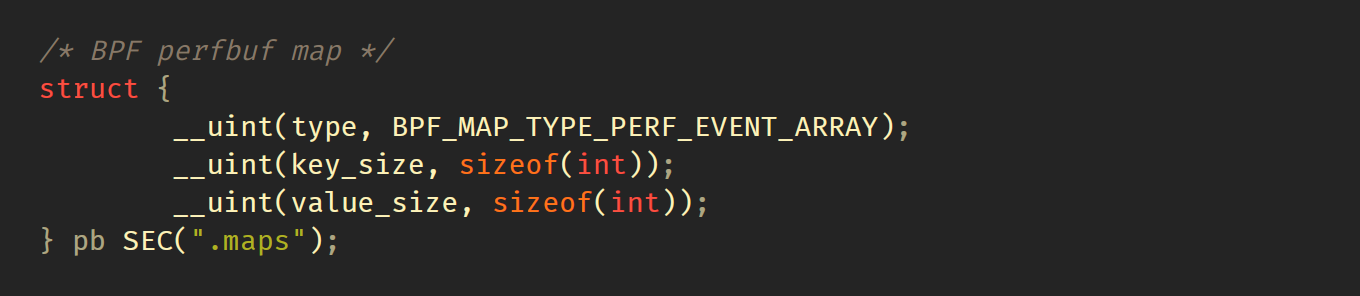
接下来,我们将定义BPF perfbuf为BPF_MAP_TYPE_PERF_EVENT_ARRAY映射。无需定义 max_entries 属性,因为 libbpf 会处理该属性,将其自动调整为系统上可用CPU数量。每个CPU缓冲区的大小不与用户空间共享,需要单独定义,接下来我们将会介绍。
如下图所示,数据结构event定义在common.h中,其中我们将filename的最大值设为512字节,所以样本占用字节大于 512字节,所以无法在堆栈上保存。 因此,我们将使用单元素单CPU数组作为临时存储:
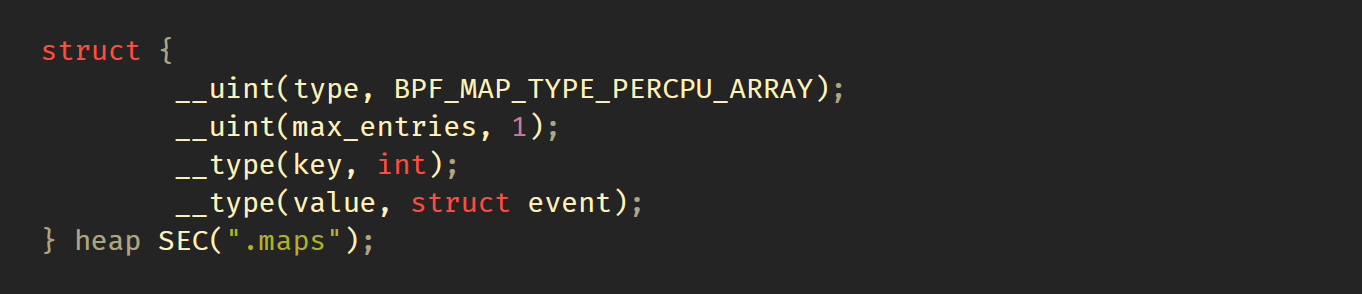
现在,我们将定义BPF程序,指定将其附加到sched:sched_process_exec上,该跟踪点将在每个成功调用系统调用exec()上触发。struct trace_event_raw_sched_process_exec也定义在common.h中,仅是从Linux源代码的复制/粘贴。该数据结构定义了该跟踪点的输入数据。
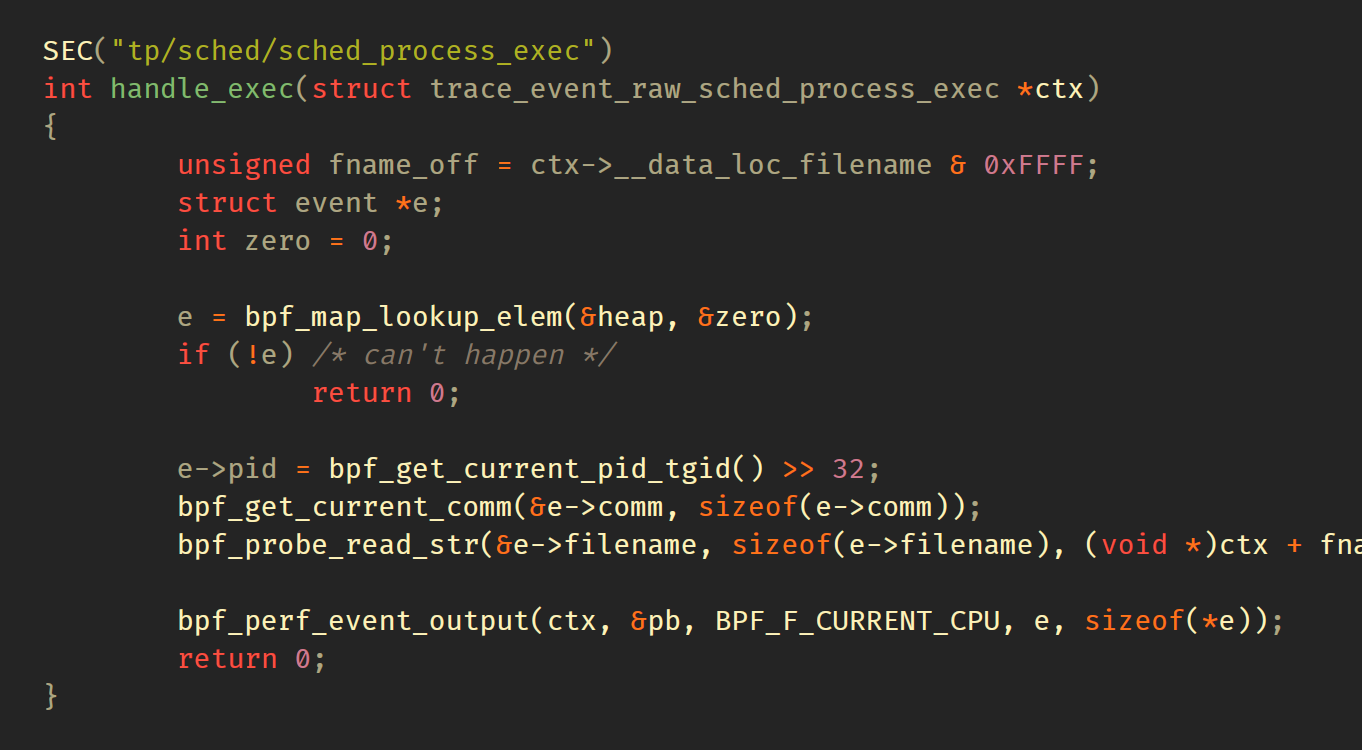
BPF程序逻辑非常简单。为样本获取一个临时存储,并用跟踪点上下文中的数据填充它。完成后,它将通过调用 bpf_perf_event_output() 将发送样本到BPF perfbuf。该 API 会在当前 CPU 的 perf 缓冲区中为数据结构 event 预留空间,将数据从 e 的sizeof(* e) 字节复制到该预留空间,完成后将向用户空间发出新数据可用的信号。此时,epoll 子系统将唤醒用户空间处理程序,并将指针传递到该数据副本进行处理。
实际上,这就是BPF程序的全部内容。如果你曾经见过任何其他BPF程序,那么该程序对你而已会非常简单。
现在让我们查看用户空间部分。该部分依靠于BPF框架,比较短小简单。关于BPF框架,你可以在此处了解更多信息。完成最小的初始设置后,例如:设置 libbpf 日志处理程序,中断处理程序,提高 BPF 系统的 RLIMIT_MEMLOCK 限制,它只会打开并加载BPF框架。如果一切成功,我们将使用 libbpf 用户空间的 perf_buffer__new() API 创建一个 perf 缓冲区使用实例:
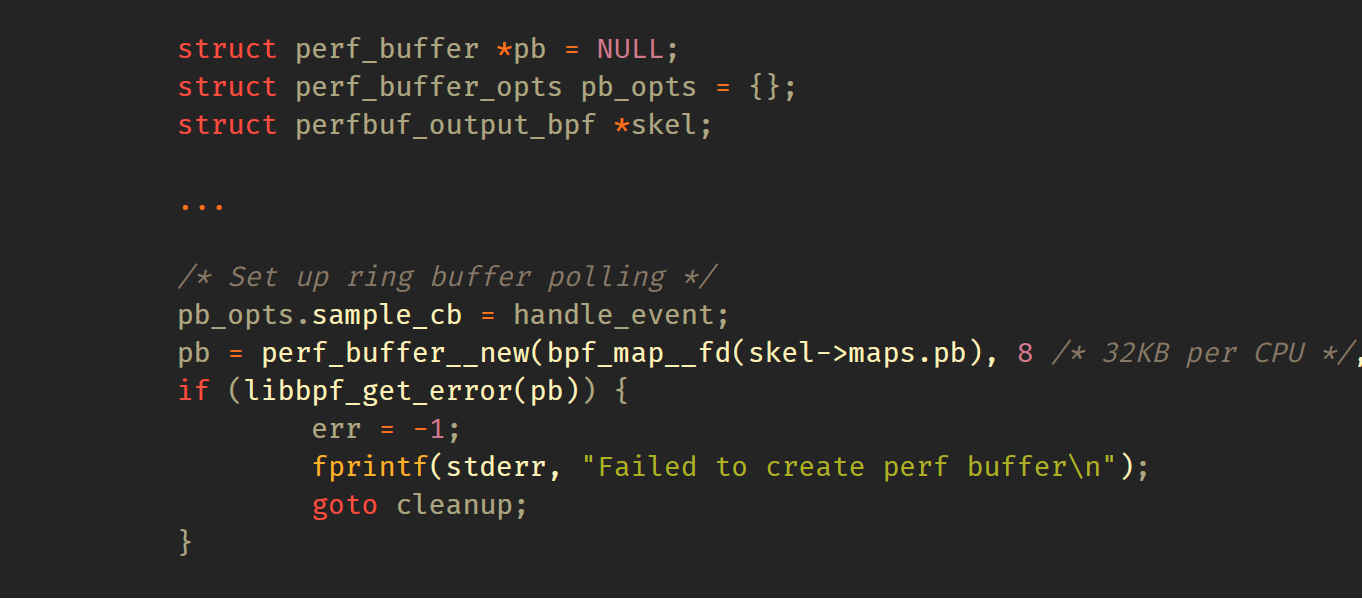
这里,我们指定每个CPU缓冲区为 32 KB,8X4096,即 8页,每4096字节。对于提交样本,libbpf将调用 handle_event() 回调,该回调仅调用 printf() 打印数据:
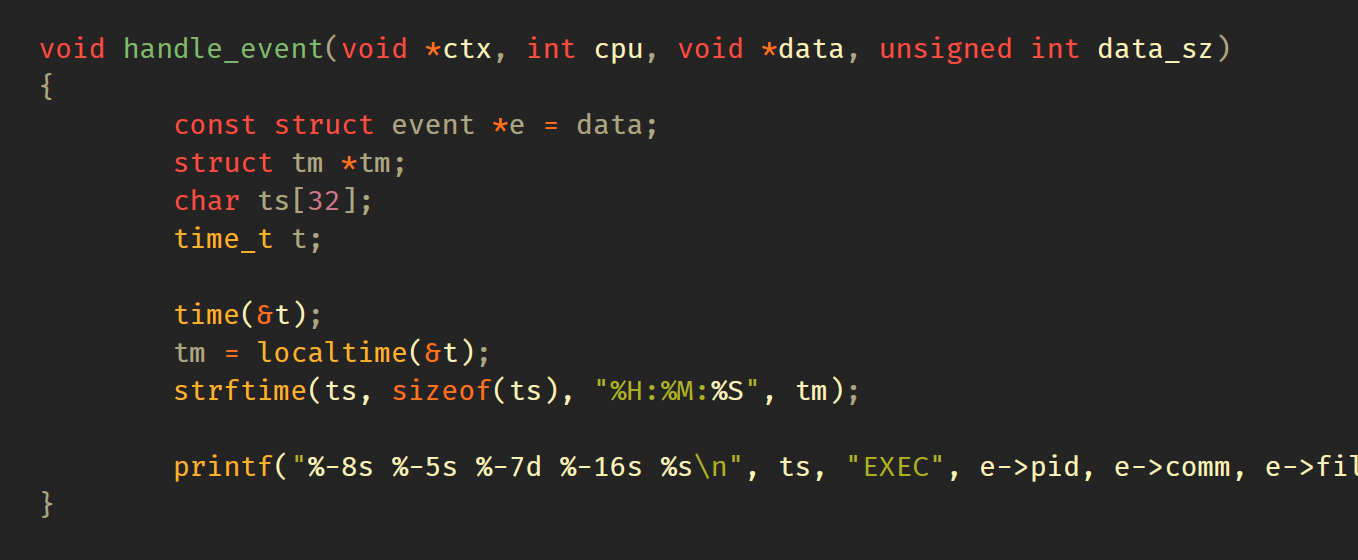
最后一步是只要有可用数据就持续打印数据,直到需要退出为止(例如,如果用户按Ctrl-C):
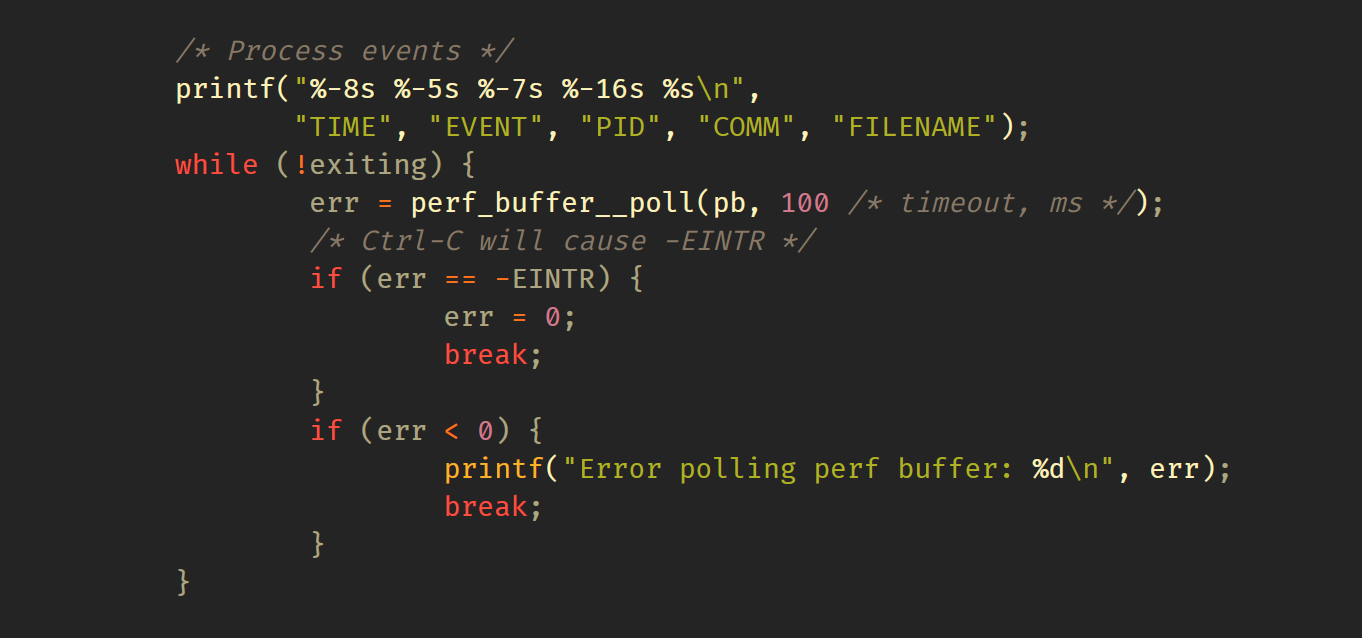
BPF ringbuf: bpf_ringbuf_output()
BPF ringbuf 中的 bpf_ringbuf_output() API 设计遵循 BPF perfbuf 中的bpf_perf_event_output() 的语义,从而使迁移过程变得轻而易举。为了演示相似性和类似的可用性,我将逐字显示 perfbuf-output 和 ringbuf-output 示例之间的区别。 你可以在Github 上查看完整的BPF侧代码和用户空间代码。
下面是BPF侧的差异:
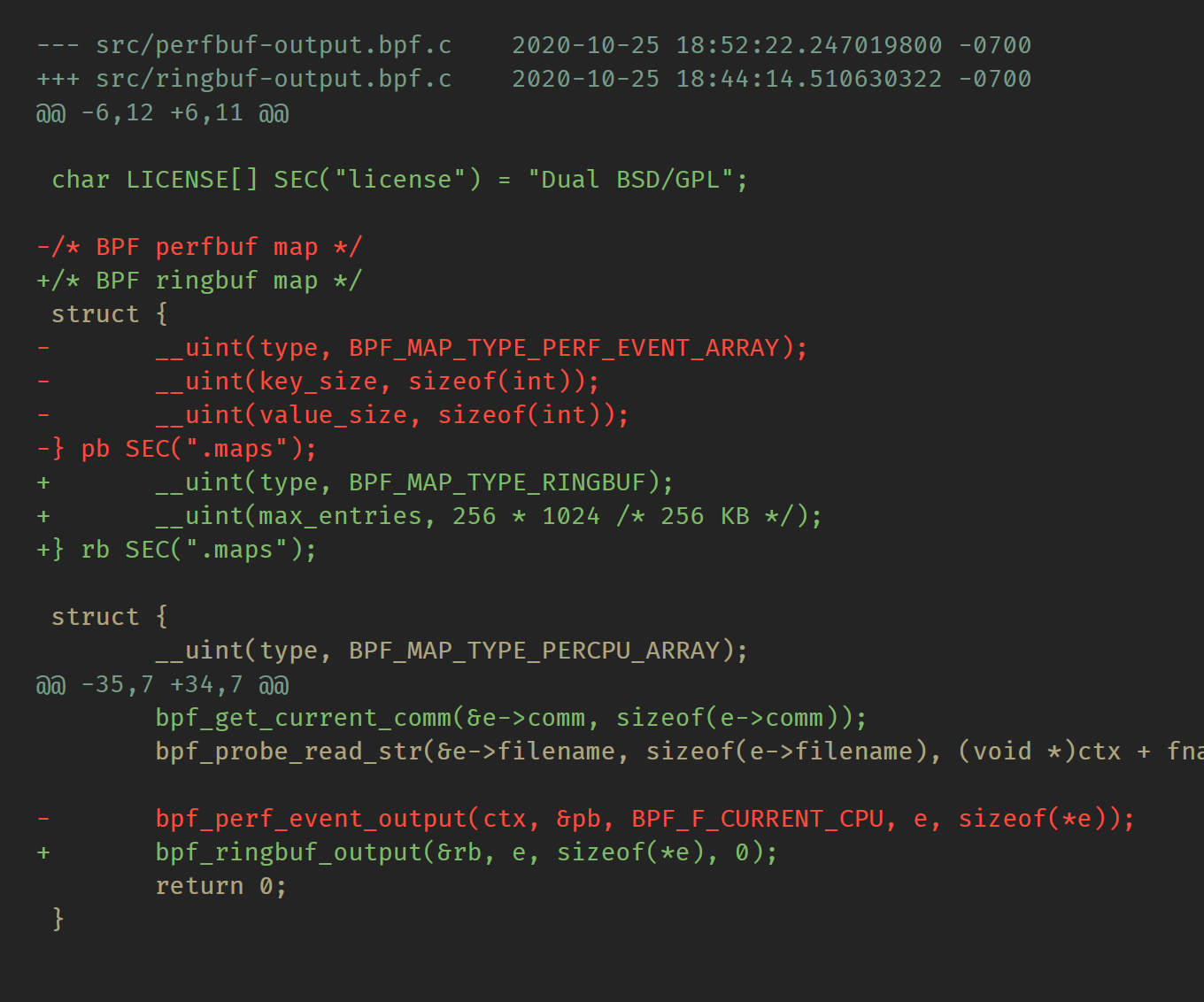
这里只有两个简单的更改:
-
BPF ringbuf 映射定义略有不同,其大小可以在BPF侧定义,并且是所有CPU共享的缓冲区。记住 也可以不在BPF 端指定大小,用户空间使用 bpf_map__set_max_entries() API指定,如果BPF侧已经指定其大小,会被覆盖。另一个区别是max_entries属性以字节数指定,唯一限制是它的大小应该是内核页大小(4096字节)的倍数,或者类似于perfbuf页数,必须是2次方。BPF perfbuf 大小是从用户空间侧指定,并且在多个内存页中。
-
bpf_perf_event_output()类似于bpf_ringbuf_output(),是bpf_ringbuf_output()的替代,唯一的区别是 ringbuf API 不需要引用 BPF 程序上下文。
以上是BPF侧仅有的两个区别。
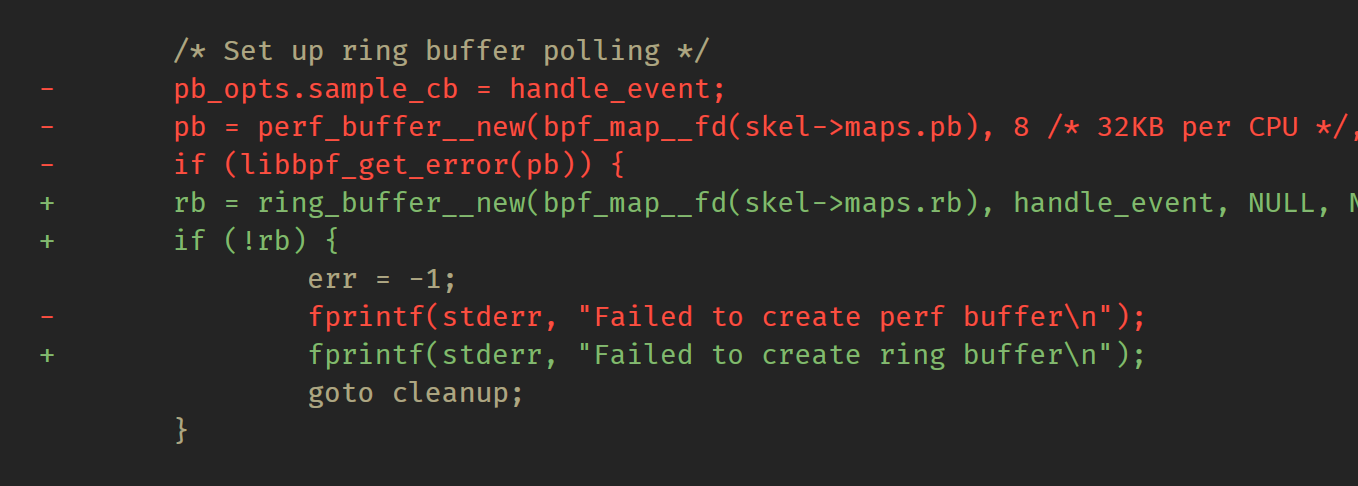
用户空间代码的更改也很小。如果忽略 perf_buffer <-> ring_buffer重命名,可以归结为两处更改。首先,事件处理程序回调可以定义错误返回,这将终止事件处理的循环,并且不占用那个产生事件的CPU:

如果知道CPU索引号很重要,则需要从BPF侧显式地将其记录在样本中。 另外,ring_buffer API 不提供丢失样本的回调,而 perf_buffer 会提供此回调。若有需要,这也可从 BPF侧进行处理。这样做是为了最大程度地减少共享(跨CPU)环形缓冲区中的锁竞争,和在不需要时减少程序付出的代价。另外,在实践中,除了记录数据之外,几乎不做其他的,这可以通过显式BPF代码更有效、更方便地实现。
第二个区别是一个更简单的ring_buffer__new() API,允许不使用额外选项数据结构下指定回调:
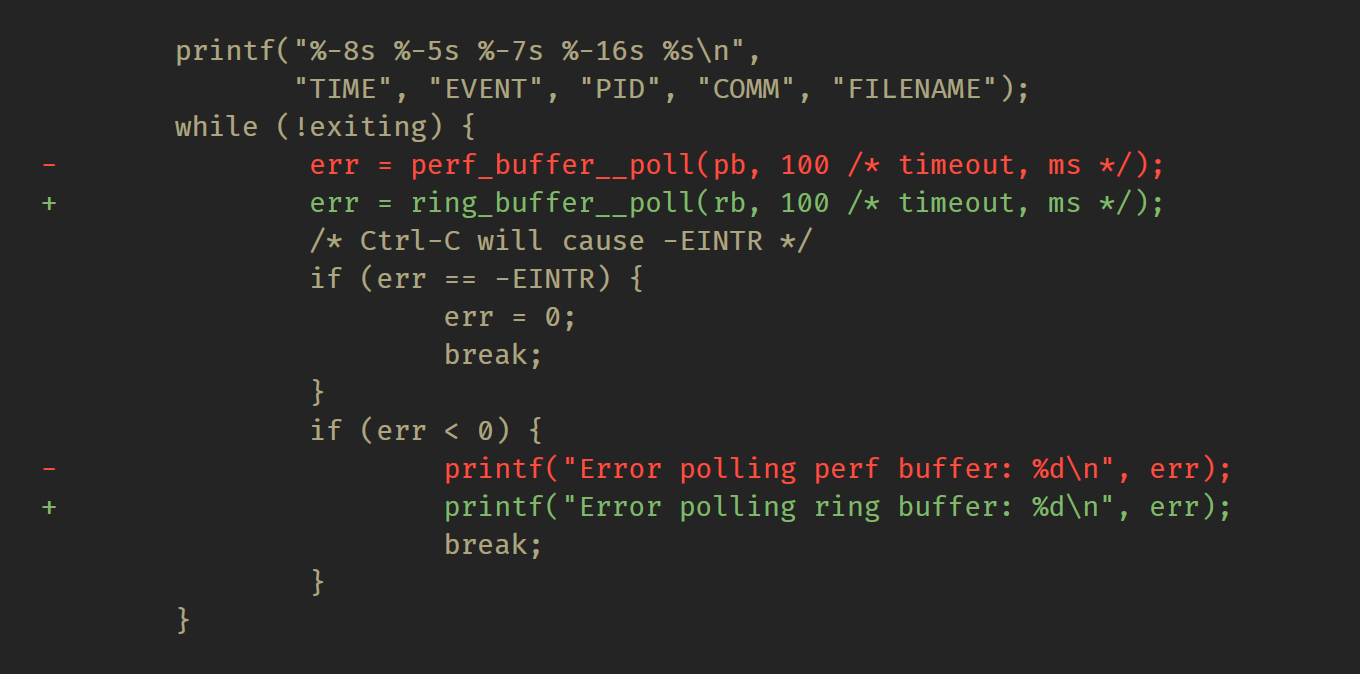
这样,只需使用ring_buffer__poll() 替换 perf_buffer__poll(),即可以完全相同的方式使用环形缓冲区数据:
BPF ringbuf: reserve/commit API
bpf_ringbuf_output() API的目的是允许从 BPF perfbuf 平滑过渡到 BPF ringbuf,而无需对BPF 代码进行任何实质性更改。但这也意味着它具有 BPF perfbuf API 的一些缺点:额外的内存复制和滞后的数据预留。前者意味着你需要额外的空间来构造样本,然后再将其复制到缓冲区中。这不仅效率低下,而且对于单元素单CPU阵列经常需要额外的复杂性。后者意味着,如果由于滞后的用户空间或由于传入事件的快速爆发,使缓冲区溢出而导致缓冲区中没有剩余空间,则构建样本的所有工作会浪费。但是,如果你知道无论如何都会删除数据,则可以首先跳过收集数据,并节省一些资源以使用户方更快地捕获数据。但是使用xxx_output() 风格的API是不可能的。
这里 bpf_ringbuf_reserve()/bpf_ringbuf_commit() API就派上用场了。Reserve允许你执行以下操作:尽早预留空间或确定不可能的空间(在这种情况下返回NULL)。如果我们没有足够的数据来提交样本,则可以跳过花费所有资源来捕获数据步骤。但是,如果预留成功,那么我们可以保证,一旦完成数据收集,将其发布到用户空间将永远不会失败。即如果bpf_ringbuf_reserve() 返回一个非NULL指针,则后续的 bpf_ringbuf_commit() 将始终成功。
此外,环形缓冲区本身中的预留空间直到提交后才对用户空间可见,因此可以随意使用它来构建样本,无论它是复杂且多步骤操作。而且,它消除了额外的内存复制和临时存储空间的需求。唯一的限制是BPF验证程序必须在验证时知道预留的大小,因此必须使用bpf_ringbuf_output() 处理具有动态大小的样本,并付出额外副本的费用。
在大多数情况下,reserve/commit 是你应该首选的方法。下面是BPF程序代码的差异(完整的BPF侧和用户空间代码也位于Github上):
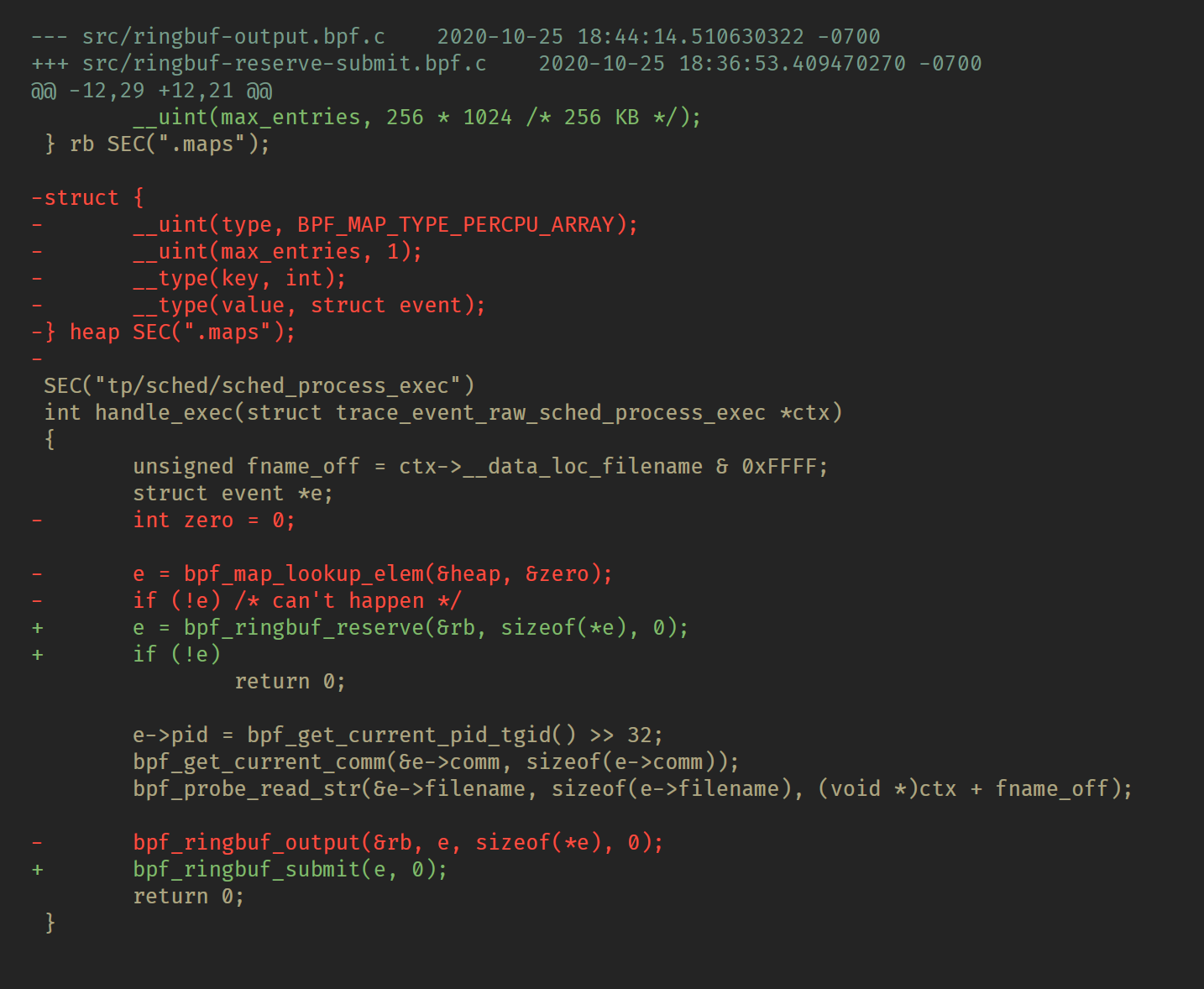
每个CPU数组已不存在,而是使用 bpf_ringbuf_reserve() 返回对象填充样本。
用户空间部分是完全相同的,BPF框架对象名为 modulo,最后你将处理来自 BPF 环形缓冲区的完全相同的数据。
BPF ringbuf: data notification control
在处理高吞吐量的情况时,通常最大的开销通常是提交样本时,内核内部发出数据可用性信号,使内核的poll/epoll系统唤醒等待新数据而阻塞的用户空间处理程序。 perfbuf 和ringbuf 都是如此。
Perfbuf 可以设置样本通知来处理此问题,在这种情况下,第N个样本都会发送一个通知。你可以从用户空间创建 BPF perfbuf 映射时执行此操作。而且,你需要确保它对你有用,直到第N个样本到来,你才可以看到最后的N-1个样本。对于特殊情况,这可能不重要。
BPF ringbuf 与此不同。 bpf_ringbuf_output() 和bpf_ringbuf_commit() 有额外的flags参数,你可以指定 BPF_RB_NO_WAKEUP 或 BPF_RB_FORCE_WAKEUP 标志。指定BPF_RB_NO_WAKEUP禁止发送内核数据可用性通知。而 BPF_RB_FORCE_WAKEUP 将强制发送通知。如果需要,这可以进行精确的手工控制。要了解如何做到这一点,请检查BPF ringbuf 基准测试,该基准测试仅在环形缓冲区中放入可配置的数据量时才发送通知。
默认情况下,如果未指定标志,则 BPF ringbuf 代码将根据用户空间使用方是否滞后来进行自适应通知,这将导致用户空间使用方从不丢失单个样本通知,但不会付出不必要的代价。默认没有一个flag是好的和安全的,但是如果你需要获得额外的性能,则根据你的自定义条件,例如:缓冲区中排队的数据量,手工控制数据通知可能会大大提高性能。
结论
这篇文章解释了 BPF 环形缓冲区正在解决的问题以及 API 选择背后的动机。希望通过代码示例以及指向内核自测和基准的额外链接,可以使你对BPF ringbuf API有所了解,并演示了API 的简单和更高级用法,以满足你的应用程序需求。
- 原文作者:范彬
- 原文链接:https://www.ebpf.top/post/bpf_ring_buffer/
- 版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议. 进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。
- 最后更新时间:2022-11-05 21:36:51.853312162 +0800 CST

